Web and Internet
| Catégorie | Cours |
|---|---|
| Ordre d'apprentissage | 1 |
| Statut | Préparé |
Cours de Julie Chaumard
To Do
| Chapters | Homeworks | Exercises | Weeks | Dates |
|---|---|---|---|---|
| Web and Internet | 1 | 02/06/2025 | ||
Ressources
- W3C consortium: https://www.w3.org
- w3schools consortium: https://www.w3schools.com
- Mozilla developer: https://developer.mozilla.org/fr/
- PHP documentation: http://php.net
- PDF AI in software development: /Users/juliechaumard/Library/CloudStorage/GoogleDrive-juliechaumard@gmail.com/Mon Drive/formations/schiller/cours/CS 280 - Web dev/ai_in_software_dev.pdf
Web Architecture
Web vs Internet
Static vs Dynamic website
The web is sometimes referred to as a client-server model of communications. In the client-server model, there are two types of actors: clients and servers. The server is a computer agent that is normally active 24/7, listening for requests from clients. A client is a computer agent that makes requests and receives responses from the server, in the form of response codes
Front-end vs Back-end
Front-end
In the browser
In the earliest days of the web, users could read the pages but could not provide feedback. The early days of the web included many encyclopedic, collection-style sites with lots of content to read (and animated icons to watch).
In those early days, the skills needed to create a website were pretty basic: one needed knowledge of HTML and perhaps familiarity with editing and creating images. This type of website is commonly referred to as a static website, in that it consists only of HTML pages that look identical for all users at all times.
Back-end
sites began to get more complicated as more and more sites began to use programs running on web servers to generate content dynamically. These server-based programs would read content from databases, interface with existing enterprise computer systems, communicate with financial institutions, and then output HTML that would be sent back to the users' browsers. This type of website is called a dynamic server-side website because the page content is being created at run time by a program created by a programmer; this page content can vary from user to user.
So while knowledge of HTML was still necessary for the creation of these dynamic websites, it became necessary to have programming knowledge as well. Moreover, by the late 1990s, additional knowledge and skills were becoming necessary, such as CSS, usability, and security.
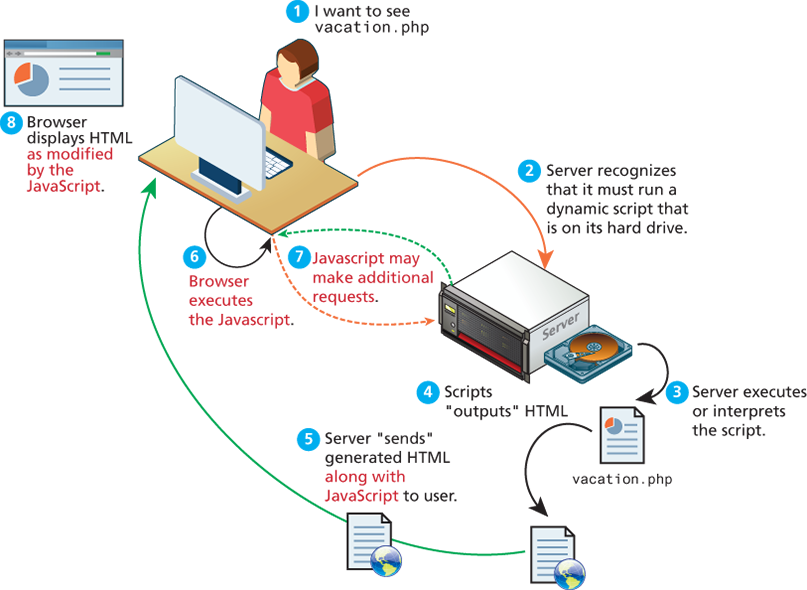
In this figure, there is php and javascript that represent the web 2.0. Before web 2.0, only php and request where proceded.
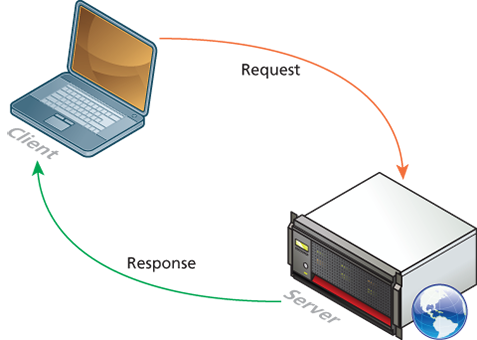
Client-server
The web is sometimes referred to as a client-server model of communications. In the client-server model, there are two types of actors: clients and servers. The server is a computer agent that is normally active 24/7, listening for requests from clients. A client is a computer agent that makes requests and receives responses from the server, in the form of response codes
Client
Client machines are the desktops, laptops, smart phones, and tablets you see everywhere in daily life.
Server
The server in this model is the central repository, the command center, and the central hub of the client-server model. It hosts web applications, stores user and program data, and performs security authorization tasks. Since one server may serve many thousands, or millions of client requests, the demands on servers can be high. A site that stores image or video data, for example, will require many terabytes of storage to accommodate the demands of users. A site with many scripts calculating values on the fly, for instance, will require more CPU and RAM to process those requests in a reasonable amount of time.
The essential characteristic of a server is that it is listening for requests, and upon getting one, responds with a message. The exchange of information between the client and server is summarized by the request-response loop.
Web servers. A web server is a computer servicing HTTP requests. This typically refers to a computer running web server software, such as Apache or Microsoft IIS (Internet Information Services).
Application servers. An application server is a computer that hosts and executes web applications, which may be created in PHP, ASP.NET, Ruby on Rails, or some other web development technology.
Database servers. A database server is a computer that is devoted to running a Database Management System (DBMS), such as MySQL, Oracle, or MongoDB, that is being used by web applications.
Mail servers. A mail server is a computer creating and satisfying mail requests, typically using the Simple Mail Transfer Protocol (SMTP).
Media servers. A media server (also called a streaming server) is a special type of server dedicated to servicing requests for images and videos. It may run special software that allows video content to be streamed to clients.
Authentication servers. An authentication server handles the most common security needs of web applications. This may involve interacting with local networking resources, such as LDAP (Lightweight Directory Access Protocol) or Active Directory.
server farms
A busy site can receive thousands or even tens of thousands of requests a second; globally popular sites such as Facebook receive millions of requests a second.
A single web server that is also acting as an application or database server will be hard-pressed to handle more than a few hundred requests a second, so the usual strategy for busier sites is to use a server farm. The goal behind server farms is to distribute incoming requests between clusters of machines so that any given web or data server is not excessively overloaded. Special devices called load balancers distribute incoming requests to available machines.
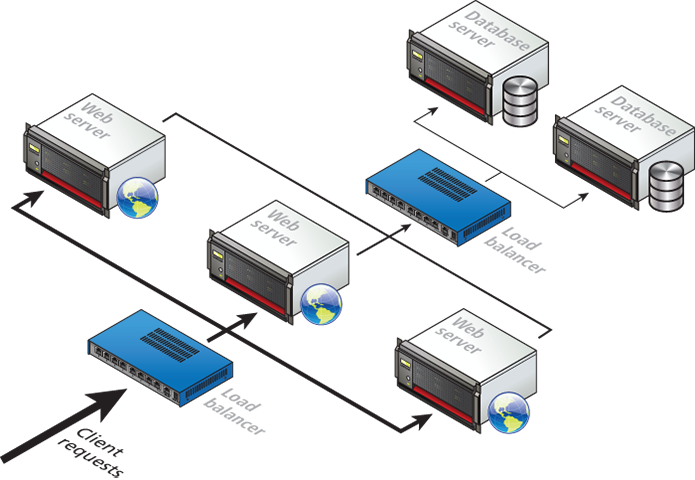
Failover redundancy
Even if a site can handle its load via a single server, it is not uncommon to still use a server farm because it provides failover redundancy; that is, if the hardware fails in a single server, one of the replicated servers in the farm will maintain the site's availability.
In a server farm, the computers do not look like the ones in your house. That is, a farm will have its servers and hard drives stacked on top of each other in server racks. A typical server farm will consist of many server racks, each containing many servers. These racks are located in Datacenters
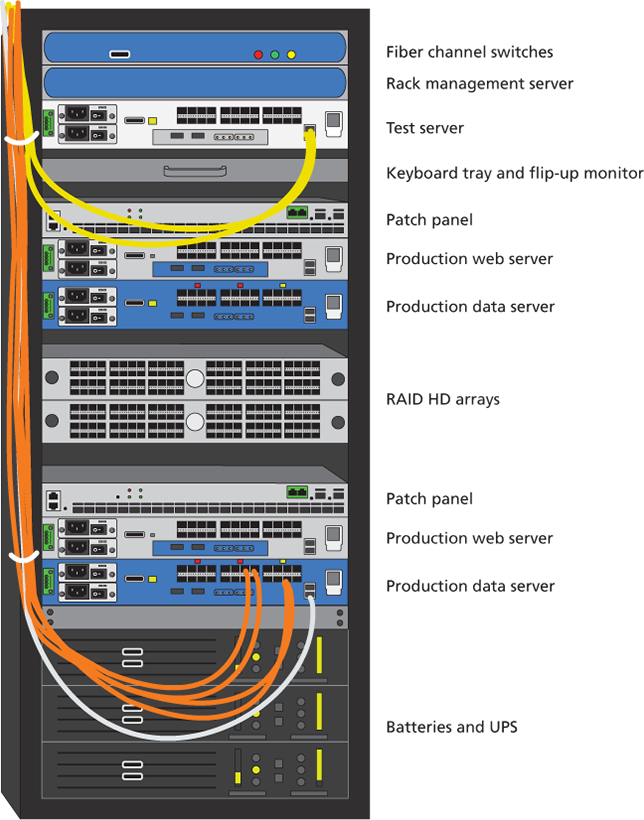
Data center
Server farms are typically housed in special facilities called data centers. A data center will contain more than just computers and hard drives; sophisticated air conditioning systems, redundancy power systems using batteries and generators, specialized fire suppression systems, and security personnel are all part of a typical data center
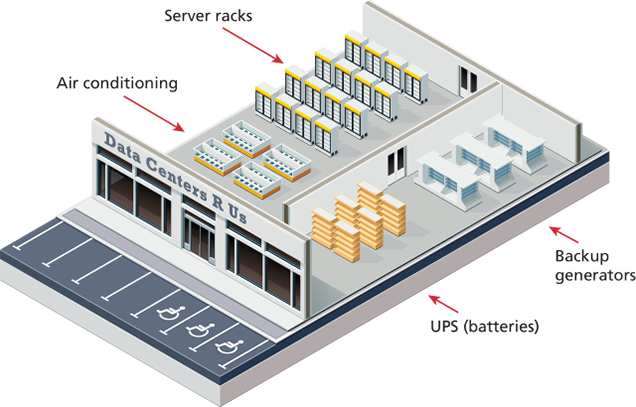
To prevent the potential for site downtimes, most large websites will exist in mirrored data centers in different parts of the country, or even the world. As a consequence, the costs for multiple redundant data centers are quite high (not only due to the cost of the infrastructure but also due to the very large electrical power consumption used by data centers), and only larger web companies can afford to create and manage their own. Most web companies will instead lease space from a third-party data center.
The scale of the web farms and data centers for large websites can be astonishingly large. While most companies do not publicize the size of their computing infrastructure, some educated guesses can be made based on the publicly known IP address ranges and published records of a company's energy consumption and their power usage effectiveness. In 2013, Microsoft CEO Steve Ballmer provided some insight into the vast numbers of servers used by the largest web companies: “We have something over a million servers in our data center infrastructure. Google is bigger than we are. Amazon is a little bit smaller. You get Yahoo! and Facebook, and then everybody else is 100,000 units probably or less.
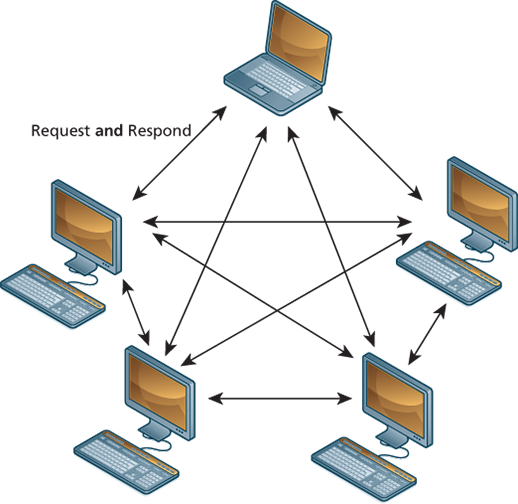
Peer-to-Peer architecture
In the peer-to-peer model, where each computer is functionally identical, each node (i.e., computer) is able to send and receive data directly with one another. In such a model, each peer acts as both a client and server, able to upload and download information. Neither is required to be connected 24/7, and each computer is functionally equal. The client-server model, in contrast, defines clear and distinct roles for the server. Video chat and bit torrent protocols are examples of the peer-to-peer model.
Web languages Front-End
- HTML
- CSS
- JS
Web languages Back-End
- php
- python
- java
- js avec Node
- C++
- Swift
- Kotlin
- SQL
Web development categories
- Web site
- Web application
- Web 2.0
In the mid-2000s, a new buzzword entered the computer lexicon: Web 2.0. This term had two meanings, one for users and one for developers. For the users, Web 2.0 referred to an interactive experience where users could contribute and consume web content, thus creating a more user-driven web experience. Some of the most popular websites today fall into this category: Facebook, YouTube, and Wikipedia. This shift to allow feedback from the user, such as comments on a story, threads in a message board, or a profile on a social networking site has revolutionized what it means to use a web application.
For software developers, Web 2.0 also referred to a change in the paradigm of how dynamic websites are created. Programming logic, which previously existed only on the server, began to migrate to the browser. This required learning JavaScript (AJAX or Fetch), a rather tricky programming language that runs in the browser, as well as mastering the rather difficult programming techniques involved in asynchronous communication.
URL & Domain
- URL
https://www.myholidayinrome.com
https://myholidayinrome.com
https://www.google.com
https://google.com
https://blog.mozilla.org
- Protocol
- HTTP. The Hypertext Transfer Protocol is used for web communication.
- SSH. The Secure Shell Protocol allows remote command-line connections to servers.
- FTP. The File Transfer Protocol is used for transferring files between computers.
- POP/IMAP/SMTP. Email-related protocols for transferring and storing email.
- DNS. The Domain Name System protocol used for resolving domain names to IP addresses.
- secured
- SSL certificate
- DOMAIN
- Extension (.net .com .org .eu .be.paris)
- look at buy a domain on OVH
- DNS
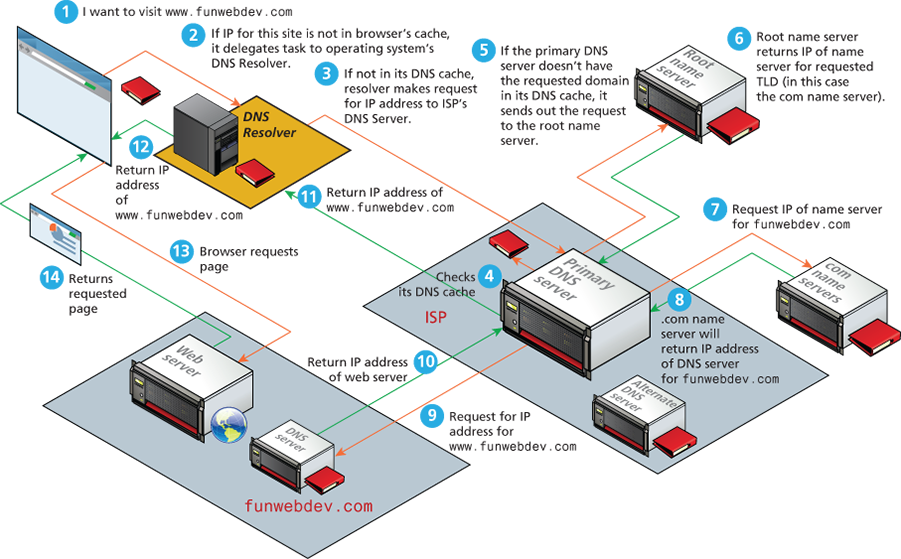
While domain names are certainly an easier way for users to reference a website, eventually your browser needs to know the IP address of the website in order to request any resources from it. DNS provides a mechanism for software to discover this numeric IP address. This process is referred to as address resolution.
As shown back in Figure 2.6 , when you request a domain name, a computer called a domain name server will return the IP address for that domain. With that IP address, the browser can then make a request for a resource from the web server for that domain.
While Figure 2.6 provides a clear overview of the address resolution process, it is quite simplified. What actually happens during address resolution is more complicated, as can be seen in Figure 2.9
Every web developer should understand the practice of pointing the name servers to the web server hosting the site. Quite often, domain registrars can convince customers into purchasing hosting together with their domain. Since most users are unaware of the distinction, they do not realize that the company from which you buy web space does not need to be the same place you register the domain. Those name servers can then be updated at the registrar to point to any name servers you use. Within 48 hours, the IP-to-domain name mapping should have propagated throughout the DNS system so that anyone typing the newly registered domain gets directed to your web server..
Environment
- web serveur
- Apache
- Nginx
- php engine
- Web browser
- Safari
- Chrome
- EDGE
- Firefox
⇒ Mozilla compatibility sheet
- developer computer
- mamp
- xampp
- laragon (xampp like)
- Filezilla for FTP
- Code editor like VSC or Jetbrains
Internet provider
- OVH
- Look for Providers
The web professions
- a webmaster
- the person who was responsible for creating and supporting a website
- He published web pages and periodically updated them
- programmers
- full-stack developer
- designers
Roles and Skills
Types of Web Development Companies

Internet
Where is Internet
It is quite common for the Internet to be visually represented as a cloud, which is perhaps an apt way to think about the Internet given the importance of light and magnetic pulses to its operation. To many people using it, the Internet does seem to lack a concrete physical manifestation beyond our computer and cell phone screens.
But it is important to recognize that our global network of networks does not work using magical water vapor, but is implemented via millions of miles of copper wires and fiber-optic cables connecting millions of server computers and probably an equal number of routers, switches, and other networked devices, along with thousands of air conditioning units and specially constructed server rooms and buildings.
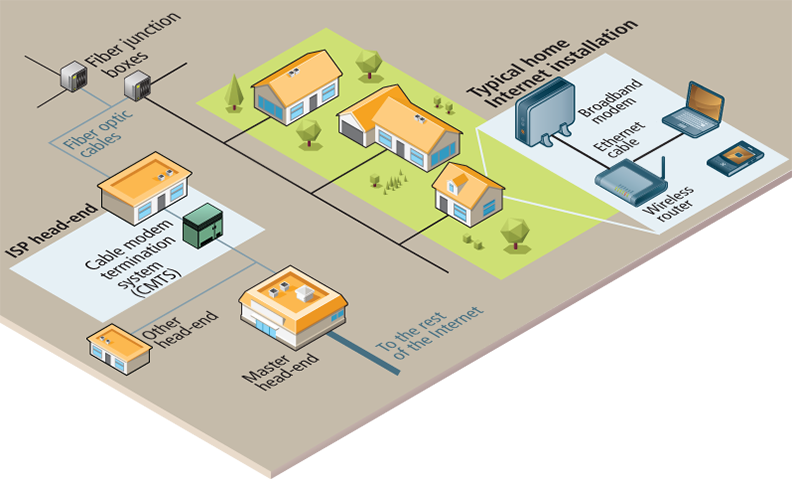
The term “ISP head end” (or simply “headend” in the context of Internet Service Providers) refers to the centralized location where an Internet Service Provider (ISP) gathers, manages, and redistributes the services it delivers to end customers.
The broadband modem, also called a cable modem or DSL (digital subscriber line) modem, is a bridge between the network hardware outside the house (typically controlled by a phone or cable company) and the network hardware inside the house. These devices are often supplied by the ISP.
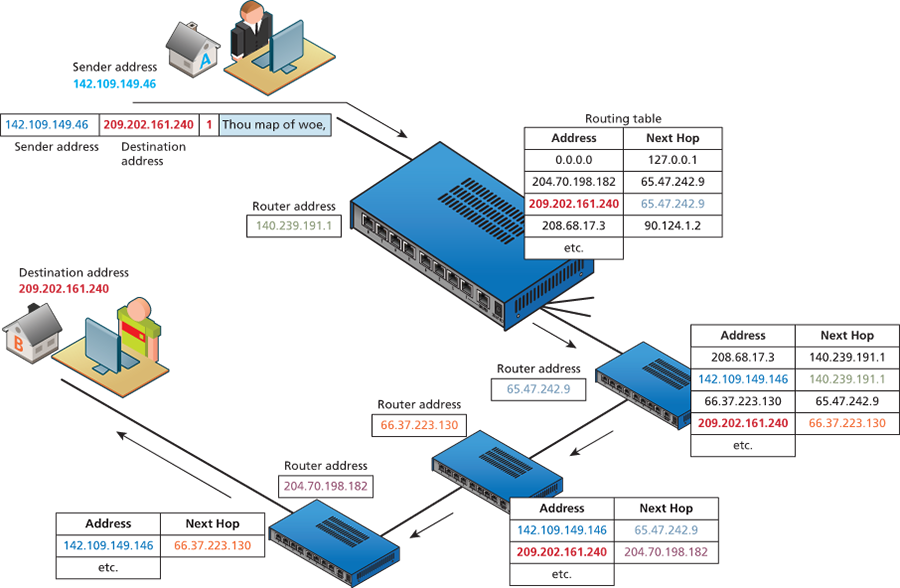
Routers are in fact one of the most important and ubiquitous hardware devices that make the Internet work. At its simplest, a router is a hardware device that forwards data packets from one network to another network. When the router receives a data packet, it examines the packet's destination address and then forwards it to another destination.
A router uses a routing table to help determine where a packet should be sent. It is a table of connections between target addresses and the destination (typically another router) to which the router can deliver the packet. The different routing tables use next-hop routing, in which the router only knows the address of the next step of the path to the destination; it leaves it to that next step to continue the routing process. The packet thus makes a variety of successive hops until it reaches its destination. Routers will make use of submasks, timestamps, distance metrics, and routing algorithms to supplement or even replace routing tables.
Fiber optic cable (or simply optical fiber) is a glass-based wire that transmits light and has significantly greater bandwidth and speed in comparison to metal wires. In some cities (or large buildings), you may have fiber optic cable going directly into individual buildings; in such a case, the fiber junction box will reside in the building.
Regional network
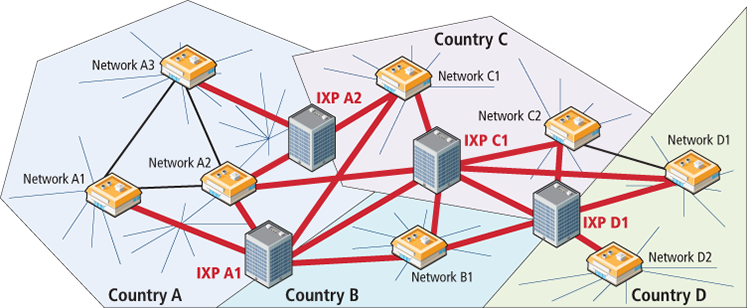
This type of network configuration began to change in the 2000s, as more and more networks began to interconnect with each other using an Internet exchange point (IX or IXP). These IXPs allow different ISPs to peer (that is, interconnect) with one another in a shared facility, thereby improving performance for each partner in the peer relationship.
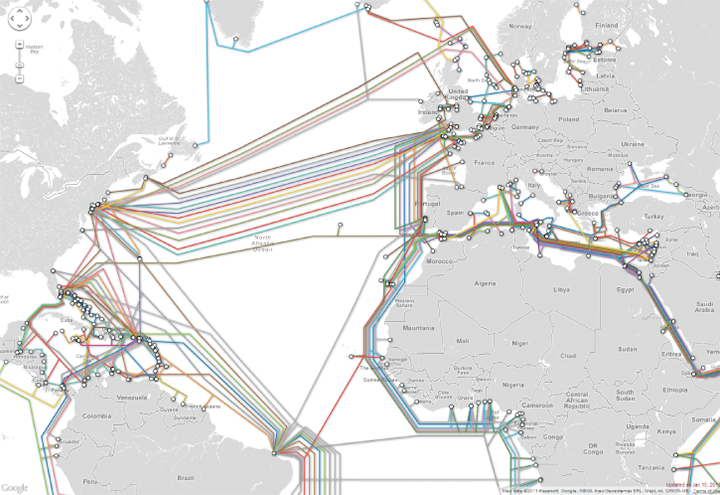
Across the Oceans
Eventually, international Internet communication will need to travel underwater. The amount of undersea fiber optic cable is quite staggering and is growing yearly. As can be seen in Figure 1.22 , over 250 undersea fiber optic cable systems operated by a variety of different companies span the globe. For places not serviced by undersea cable (such as Antarctica, much of the Canadian Arctic islands, and other small islands throughout the world), Internet connectivity is provided by orbiting satellites. It should be noted that satellite links (which have smaller bandwidth in comparison to fiber optic) account for an exceptionally small percentage of oversea Internet communication.
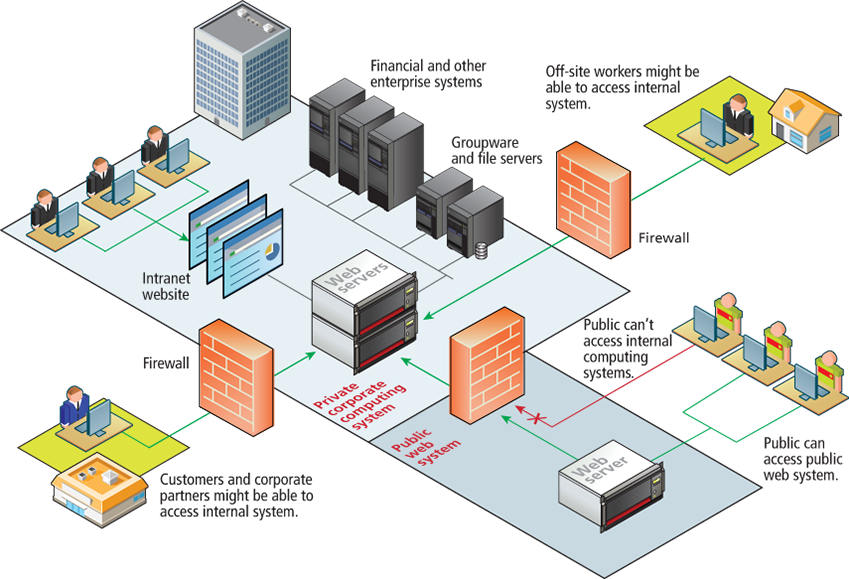
Intranet
One of the more common terms you might encounter in web development is the term “intranet”, which refers to an internal network using Internet protocols that is local to an organization or business. Intranet resources are often private, meaning that only employees (or authorized external parties such as customers or suppliers) have access to those resources.
Intranets are typically protected from unauthorized external access via security features such as firewalls or private IP ranges. Because intranets are private, search engines, such as Google have limited or no access to content within them.
The man behind the web
Sir Timothy John Berners-Lee (born 8 June 1955),[1] also known as TimBL, is an English computer scientist best known as the inventor of the World Wide Web, the HTML markup language, the URL system, and HTTP. He is a professorial research fellow at the University of Oxford[2] and a professor emeritus at the Massachusetts Institute of Technology (MIT).[3][4]
Berners-Lee proposed an information management system on 12 March 1989[5][6] and implemented the first successful communication between a Hypertext Transfer Protocol (HTTP) client and server via the Internet in mid-November.[7][8][9][10][11] He devised and implemented the first Web browser and Web server and helped foster the Web's subsequent development.
Agence digitale Parisweb.art
Tout savoir sur Julie, notre directrice de projets digitaux :
https://www.linkedin.com/in/juliechaumard/