LLM vs ML vs DL (EN)
| Catégorie | Cours |
|---|---|
| Statut | préparé |
LLM
LLM = Large Language Model
Definition
ChatGPT is an LLM, which means a Large Language Model. This means it is trained on huge volumes of text to understand, generate, rephrase, or translate human language.
An LLM is a large language model based on artificial intelligence (AI) that can process and generate text by imitating human language.
Where does the text come from?
The training texts come from very large amounts of public text data, automatically collected from the Internet.
Public websites
- Wikipedia (in all languages)
- Forums (Reddit, StackOverflow…)
- Blogs, articles, tutorials, manuals, etc.
- Q&A websites (Quora, etc.)
These texts are publicly accessible and used to teach natural language, facts, grammar rules…
Books and literature
- Public domain books (e.g., free to use)
- Academic literature, textbooks, essays, etc.
Some book datasets are legally available for training (e.g., Project Gutenberg).
Scientific and technical data
- arXiv publications (scientific preprints)
- StackExchange / GitHub data (code, documentation)
These help train the model on scientific, mathematical, and technical language…
What is NOT used:
- Private data (emails, private messages, etc.)
- Copyrighted data without explicit permission
- Paid or confidential data (internal company docs, Google Docs, etc.)
GPT-4 was also “fine-tuned” afterwards
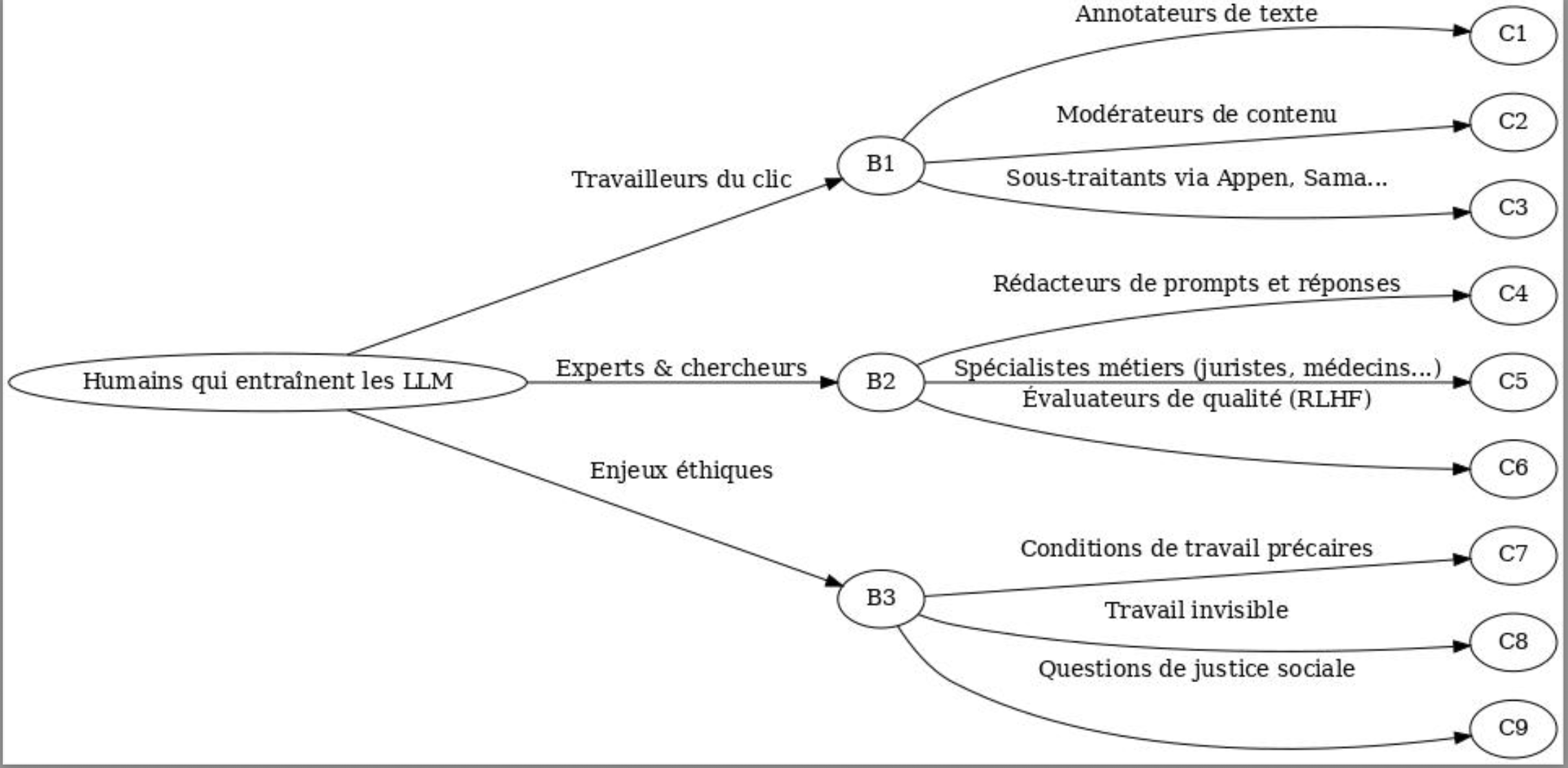
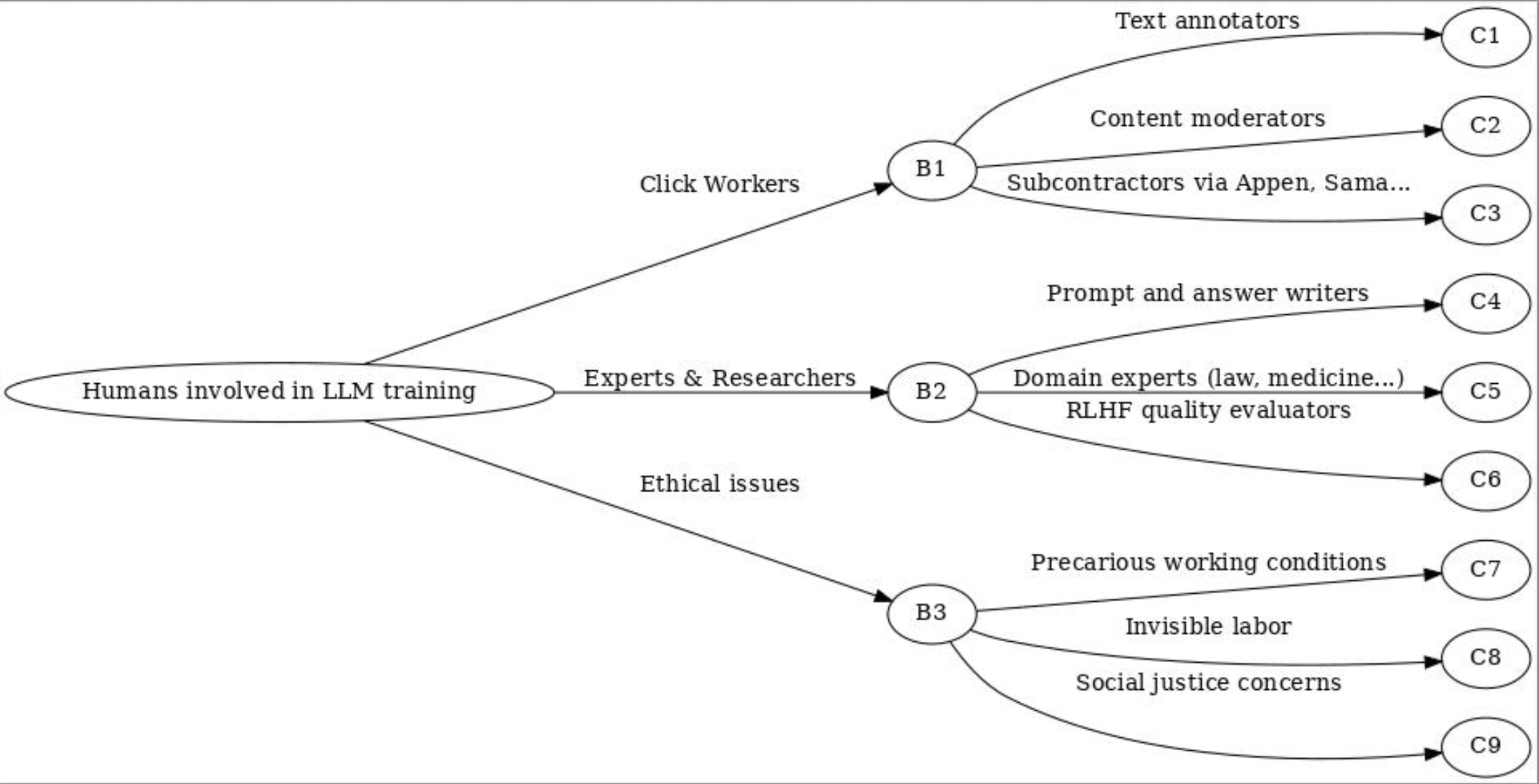
After pretraining, the model was fine-tuned using supervised learning (humans rate good answers) and reinforcement learning (to improve conversation quality). Clickworkers.
- AI may seem “magical,” but it’s based on a lot of often-invisible human work.
- This raises questions about social justice, transparency, and exploitation.
- OpenAI, Google, Meta and others are often criticized for lack of transparency and the working conditions of these workers.
What data is used to train an LLM to write code?
GitHub (public repos)
- Open-source code in Python, JavaScript, Java, C++, etc.
- Comments, README.md files, unit tests, install scripts
GPT-3 and Codex (the model behind GitHub Copilot) were trained onbillions of lines of code
StackOverflow / StackExchange
- Code examples with Q&A
- Best practices, common mistakes
Technical documentation
- Python docs, MDN Web Docs, Java API, etc.
- Framework docs (React, Django, Flask…)
Tutorials, blogs, articles
- Commented code, educational projects
- Step-by-step explanations
Specialized datasets (arXiv, Papers with Code, etc.)
- Academic code for AI, data science, etc.
How does the model learn code?
Same as with text:
- Code is turned into tokens (keywords, symbols, variable names, etc.)
- The model learns to predict the next part of an instruction
- It understands structures:
if,for,while
- Indentation
- Function and object declarations
- Error handling, tests, etc.
Most importantly: it learns to connect code with comments and business logic
Size of the training dataset
GPT-4 (2023) – data not officially published
OpenAI has not revealed the exact size of the GPT-4 dataset.
But experts estimate:
- The volume may exceed 1,000 GB to 10,000 GB of text (1 to 10 TB)
- The number of tokens (keywords, symbols, variable names, etc.) may be in the trillions
The model was also likely trained with more books, code (GitHub), technical documents, and human corrections.
| Model | Estimated text volume | Approx. word count |
| GPT-2 (2019) | ~40 GB | ~40 billion |
| GPT-3 (2020) | ~570 GB | ~250 billion |
| GPT-4 (2023) | > 1 TB | > 1 trillion (estimated) |
How LLM is working ?
These models are trained on huge amounts of text data and use advanced architectures like deep neural networks (Deep Learning), especially Transformers, introduced by Google in 2017.
An LLM follows several key steps:
- Training on billions of texts
- It learns the structure of language by analyzing texts from articles, books, online discussions, etc.
- The larger the model, the more powerful and accurate it becomes.
- Use of Transformer technology
- The Transformer architecture (e.g., GPT, BERT) uses a mechanism called “Attention” to give more importance to key words in a sentence (prompt).
- The Transformer is an AI architecture introduced by Google in 2017 (in the paper “Attention is All You Need”). It’s the base of GPT, BERT, ChatGPT, etc.
- Why was the Transformer created?
- Before, language models used systems like RNNs or LSTMs, which read sentences word by word, from left to right.
Problem:
- They had trouble with long sentences.
- They forgot what happened at the beginning of a text.
- The Transformer solved this.
- The core of the Transformer: attention. How does attention work?
- Attention does a calculation: for each word, which other words should I focus on? And how much? It gives weights (for example: 80% to “cat”, 10% to “mouse”, 10% to “was chasing”) to understand the meaning.
- Once the model finds the important words using attention, it sends this info to layers of neurons (math functions) to improve understanding and predict the next word.
- The Transformer reads the whole text in parallel (not word by word).
- That’s why GPT, BERT, and ChatGPT are so powerful.
- Examples:
“It’s very hot in summer, so I go to the…”
The model might suggest endings like: “beach”, “sea”, “pool”, etc. because these are the most likely words in that context.
The language model looks at the words before and calculates the probabilities of what comes next:
- “beach” → 62%
- “mountains” → 20%
- “pool” → 15%
- “school” → 1%
It chooses the most probable word (or one of the top choices for diversity), then repeats for the next word.
There's a lot of context:
- the model can consider full sentences,
- it's trained on billions of sentences,
- it's not guessing randomly, it’s based on what it has “seen” in the data.
“This morning, I drank a big glass of…”
Here's what the AI might predict, with estimated probabilities:
Suggested word Probability milk 45% juice 30% coffee 15% hot chocolate 5% tea 3% wine 1% vinegar 0.1% “When it rains, I like to stay home and watch…”
Word or phrase Probability TV 50% a movie 20% a series 15% Netflix 8% the rain falling 4% YouTube videos 2% nothing at all 1%
Text generation based on probabilities
- When you ask a question, the model predicts the next word based on the context.
- It generates coherent answers without truly "understanding" like a human.
Google released the Transformer as open source
When Google invented the Transformer architecture in 2017, a team from Google Brain published a paper called “Attention Is All You Need”. Most importantly, they did not patent the algorithm.
They:
- published the code and ideas,
- allowed anyone to use, modify, and improve them.
Result:
- Facebook (Meta) created BART and LLaMA
- OpenAI created GPT-2, GPT-3, GPT-4
- Google continued with BERT, then PaLM, then Gemini
- Hundreds of teams around the world also built their own Transformer models
In science, ideas are meant to be shared
In AI (and science in general), it's common to publish discoveries so that:
- everyone can benefit,
- research moves faster,
- we can build on others’ work.
Open source and scientific papers are the foundation of this collaboration.
What makes companies different?
- The amount of training data (OpenAI used much more data for GPT-4 than others)
- Computing power
- Optimization (speed, safety, alignment, etc.)
- User experience (interface, API, etc.)
Examples of Popular LLMs
- GPT (Generative Pre-trained Transformer) – Used by ChatGPT (OpenAI)
- BERT (Bidirectional Encoder Representations from Transformers) – Google
- LLaMA (Large Language Model Meta AI) – Meta (Facebook)
- Claude (Anthropic) – Another advanced model
LLMs can be specialized: code analysis, text writing, customer support, document summarization…
Applications of LLMs
- Chatbots (ChatGPT, Bard)
- Text summarization and analysis
- Machine translation (Google Translate, DeepL)
- Code generation (Copilot, Codeium)
- Content creation (articles, scripts, etc.)
Limitations and Challenges
- Bias and errors – Models learn biases from the data they are trained on.
- Lack of real reasoning – They predict words but don’t truly “understand.”
- Data dependence – A poorly trained model can produce incorrect answers.
- High energy cost – Training an LLM uses a lot of computing resources.
- It’s not like a human. The model doesn’t “understand” in a conscious way:
- It doesn’t reason like a human.
- It doesn’t know anything by itself. It repeats what it has seen in its training data, based on statistical probability.
But it is very good at imitating human language, solving problems, generating code, translating, summarizing...
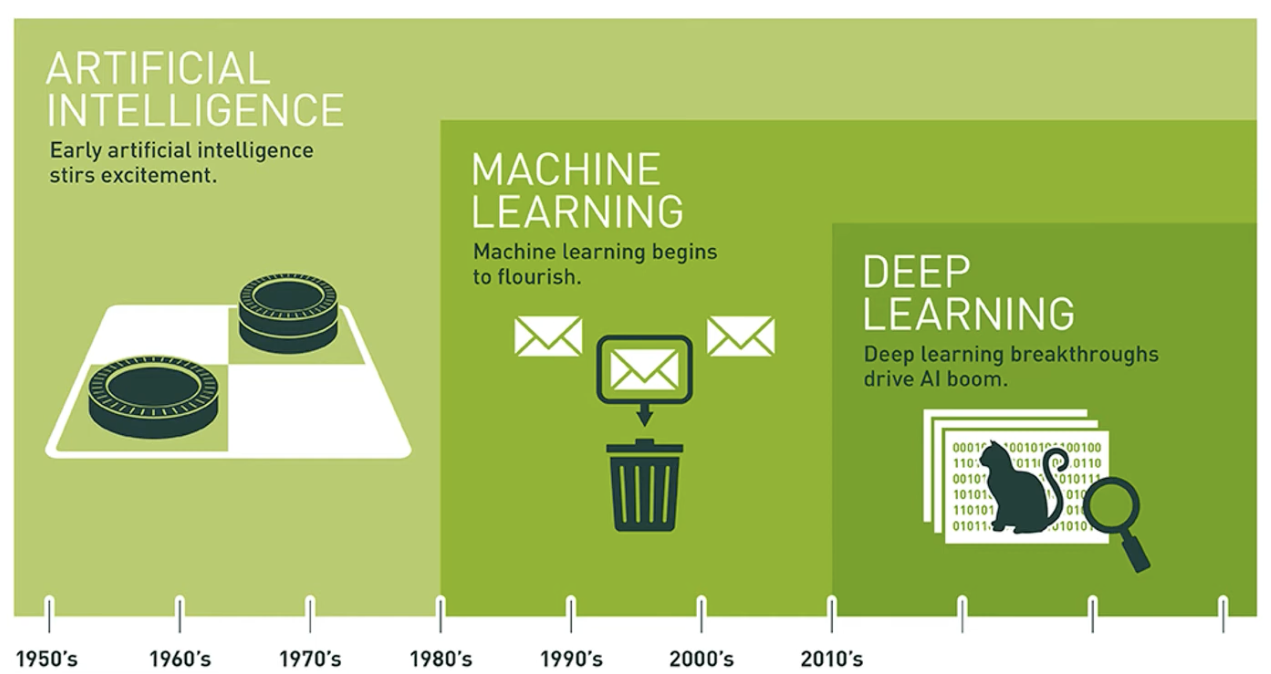
Deep Learning
Deep learning is an artificial intelligence technique that uses deep neural networks (made of multiple layers).
It can be used to:
- understand images (computer vision),
- recognize sounds (audio, voice),
- play games (intelligent agents),
- process text (NLP)...
2. LLM: an application of deep learning
An LLM (Large Language Model) is a special type of deep learning model, specialized in natural language.
Machine learning
Machine Learning is a branch of artificial intelligence that allows a machine to learn from data.
2 main types of Machine Learning
- Supervised learning
- The algorithm is given input data and the expected answers.
- Example: predicting the price of an apartment based on its size, location, etc.
- Common tasks:
- Classification (spam or not spam, disease or not)
- Regression (predicting a numeric value: price, temperature, score)
- Unsupervised learning
- The algorithm is only given input data, with no expected answers. It must discover the structure.
- Example: grouping customers into marketing segments based on purchase behavior.
- Common tasks:
- Clustering (groups, profiles)
- Dimensionality reduction (simplifying complex data, like in text or image analysis)
Example: detecting bank fraud (supervised)
- Input data: amount, location, time, type of purchase
- Expected answer: fraudulent or normal transaction
- Steps:
- Collect a historical dataset
- Train a model on this dataset
- Test the model on new data
- Use it in production to analyze transactions in real time
Common algorithms
- Linear / logistic regression
- Decision trees
Tools and languages
- Python, with libraries like scikit-learn, TensorFlow, PyTorch
- R: often used in statistics and data science
- Jupyter Notebook: for easy experimentation
- Google Colab: to test in the cloud
Create your own ML model
You can train a model on your own data to solve a specific problem (prediction, detection, recommendation…).
Steps to create a Machine Learning model
- Define the problem
What is your goal?
- Predict revenue?
- Classify emails (spam / not spam)?
- Recommend products?
- Collect the data
Reliable and well-structured data.
Examples:
- A CSV file with columns: height, weight, age, diagnosis
- A customer database with purchase history
- Prepare the data
This is often the longest step.
- Cleaning: remove missing values, duplicates
- Transformation: convert text to numbers, normalize values
- Split: divide into training set and test set
- Choose an algorithm
Examples:
- Linear regression to predict a value
- Decision tree for classification
- K-means for grouping
- Train the model
This is where the computer learns.
- Evaluate the model
Test its accuracy on data it has never seen.
- Improve the model
- Try a different algorithm
- Add more data
- Improve the features (variables)
- Use the model
You can now make predictions on new data:
Tools:
- Python with scikit-learn, pandas, matplotlib
- Google Colab to test without installing anything
- Jupyter Notebook locally
Example
Netflix is a large-scale example of Machine Learning, used in almost every part of its product. Here's how Netflix uses Machine Learning:
- Content recommendation (core system)
- Suggests series and movies each user might like.
- You watched Stranger Things and Dark? You might be shown 1899, even if you never searched for it.
- Personalized thumbnails (homepage posters)
To increase the chance you’ll click on a show.
Netflix tests different images for the same content based on your preferences:
- If you like comedies: image with a funny character
- If you like thrillers: dark and dramatic image
It’s A/B testing + supervised ML: they see what works best for each profile.
- Streaming quality prediction
Predict interruptions or slowdowns to improve streaming.
- ML on network data (location, device, streaming history…)
- Auto-adjusting quality (adaptive bitrate)
- Anticipating peak times to preload content smartly
- Content production optimization
Decide which projects to fund (movies, series), based on audience preferences.
- Analyzing engagement on genres / formats
- Predicting the success of a script, casting, duration…
- Example: House of Cards was greenlit partly because data showed people liked both Kevin Spacey and political dramas.
- Fighting fraud and account sharing
Detect suspicious behavior (excessive sharing, bots…)
- Analyzing IP addresses, times, devices
- Anomaly detection models
- Segmenting "suspicious" users
ML vs DL
| Criterion | Machine Learning (classic) | Deep Learning |
|---|---|---|
| Types of data | Tabular data (Excel, CSV) | Unstructured data (image, sound, text, video) |
| Data volume | Works with small datasets | Needs a lot of data (millions of examples) |
| Computing power | Moderate, often runs on CPU | Very high, often needs GPUs |
| Explainability | Easier to interpret | Black box, hard to explain |
| Typical AI uses | Price prediction, diagnostics, scoring | Facial recognition, translation, generative AI |
| Known tools | Scikit-learn, XGBoost | TensorFlow, PyTorch, Keras |
| Tool / Platform | Main AI type | Underlying technology | Typical uses |
|---|---|---|---|
| Scikit-learn | ML (Machine Learning) | Trees, SVM, regressions, clustering | Data analysis, simple prediction, classification |
| XGBoost / LightGBM | ML | Tree boosting | High-performance models on tabular data (finance, scoring…) |
| Orange Data Mining | ML | Graphical interface for ML algorithms | Education, visualization, classification, clustering |
| RapidMiner | ML | ML workflows | Business analytics, scoring, anomaly detection |
| TensorFlow | DL | Neural networks | Vision, audio, language processing, generative AI |
| PyTorch | DL | Neural networks | AI research, NLP, Computer Vision |
| Keras | DL (high-level) | TensorFlow abstraction | Neural network prototyping |
| OpenCV + ML | ML | Built-in SVM, kNN | Simple computer vision (object, face detection) |
| OpenCV + DL (with DNN) | DL | Pretrained CNNs | Advanced vision (real-time detection, facial recognition) |
| ChatGPT / GPT | DL | Transformer, NLP | Chat, text generation, summarization, code |
| Claude / Gemini / LLaMA | DL | Transformer | Large language models |
| DALL·E / MidJourney | DL | Diffusion models / GAN | Image generation from text |
| Whisper (OpenAI) | DL | Audio-to-text with Transformer | Speech transcription |
IA forte et IA faible
Strong AI and Weak AI
💡It's not just ChatGPT and generative AI. AI has already been used in various forms for several years.
Two main types of AI
- Strong AI (hypothetical future)
- Description: AI capable of understanding, learning, and performing any task a human can do, with similar cognitive abilities.
- Examples:
- It doesn’t exist yet in real life, but is often shown in science fiction movies, like Jarvis in Iron Man.
- Goal: To be as flexible and intelligent as a human.
- A science fiction concept. For example, author Philip K. Dick.
- Many movies talk about it:
- Westworld
- Detroit: Become Human (video game)
- A.I. Artificial Intelligence by Steven Spielberg, based on an idea by Stanley Kubrick (2001)
- Synopsis: In a future where AIs are humanoid robots, a robot boy named David, designed to love, desperately tries to become "human."
- Why watch it? The film explores the identity and emotions of AI, and questions what it means to be human.
- I, Robot by Alex Proyas (2004)
- Synopsis: Based on works by Isaac Asimov, this film follows a detective investigating a murder possibly involving a robot. It explores moral dilemmas around intelligent robots.
- Why watch it? It questions how humans and strong AI could coexist in a world governed by ethical laws for robots.
- Her by Spike Jonze (2013)
- Synopsis: Theodore, a lonely man, develops an intimate relationship with an intelligent operating system named Samantha. Samantha evolves by learning from interactions with Theodore.
- Why watch it? The film discusses the emotional and social impact of AIs that can feel and understand human emotions.
- Ex Machina by Alex Garland (2014)
- Synopsis: A young programmer is invited by a billionaire to test the intelligence of a humanoid robot named Ava, who has advanced AI. The film explores ethical, emotional, and philosophical questions about strong AI.
- Why watch it? It raises deep questions about consciousness, free will, and the relationship between humans and machines.
- Ghost in the Shell by Rupert Sanders (2017)
- Synopsis: In a cybernetic world, a cyborg investigates a hacker who challenges the boundary between human and AI.
- Why watch it? A philosophical reflection on the soul, consciousness, and the fusion of human and machine. Humans becoming robots.
- Blade Runner by Ridley Scott (1982) & Blade Runner 2049 by Denis Villeneuve (2017)
- Synopsis: In a futuristic world, "replicants" (advanced androids) try to understand their place in society.
- Why watch it? These films explore what makes intelligence (or life) authentic, examining empathy and the soul.
- Weak AI
- Description: Weak AI is designed to do a specific task. It is specialized in one single function.
- Examples:
- Google Translate
- Siri or Alexa: Voice recognition and responses
- Recommendation systems: Netflix or YouTube
- Video games: Computer-controlled opponents
- Facial recognition
- IBM’s Deep Blue: The program that beat chess champion Garry Kasparov in 1997
- Self-driving cars: They analyze roads, signs, and other vehicles in real time
- Medical diagnosis: Scientists collect medical knowledge and build logic rules for the AI. The AI analyzes symptoms and test results to suggest possible causes and make diagnoses.
These AIs are already used by doctors to help diagnose rare or complex diseases.
- Content creation: helping creators save time, improve quality, and generate innovative ideas.
- Automated writing: Language models like GPT can write articles, blogs, product descriptions, emails, and more.
- Rewriting help: Rephrasing sentences or paragraphs to make them clearer or more convincing.
- Summarizing: Turning complex documents into short summaries.
- Idea generation: Suggesting catchy titles, content topics, or original angles.
- Research and information gathering: AI can help find specific info or analyze trends.
- Editorial planning: Suggest publishing calendars based on past performance and market trends.
- Performance analysis: Measure impact and suggest adjustments (titles, formats, visuals).
- AI acts like a powerful assistant to speed up creation, improve quality, and open new creative possibilities — while keeping humans at the center of decision-making.
- Chatbots that only answer predefined questions and can't adapt to complex situations
- ChatGPT is designed to do a specific task: generate text and respond to questions in a coherent and relevant way. It doesn’t have general understanding or consciousness like a human. ChatGPT is an advanced example of weak AI — it is excellent at one particular task (natural language processing) without having the general or adaptive abilities of strong AI.
- Automation and robotics:
- Robotic machines learn automatically to improve and speed up movements. For example, in a production line.
- Machines are designed to communicate with each other. A designer at the beginning shows the product plan, then the machines work and coordinate to complete it by themselves.
- Limitation: It doesn’t "understand" the task. It follows defined algorithms. Even if its responses seem smart, it doesn’t truly understand what it's saying. It uses statistical models to predict words based on the data it was trained on.
ChatGPT cannot solve problems outside its predefined scope (for example, it can’t drive a car, design an electronic circuit, or reason abstractly beyond its training domain).
People
Marvin Minsky
American who created working groups and conferences in the 1950s and 1960s that led to the birth of Artificial Intelligence.
Minsky co-founded the MIT Artificial Intelligence Laboratory (now CSAIL, Computer Science and Artificial Intelligence Laboratory) with John McCarthy. This lab is one of the most influential AI research centers in the world and has contributed to major advancements in computing, robotics, and AI.
Luc Julia
French expert. Designer of Siri.
In his public speeches in France, Luc Julia takes a more balanced view on artificial intelligence; he prefers to use the term “augmented intelligence.” In his talks, he opposes the ideas of some tech personalities, like Elon Musk. For him, it is humans who are and will remain in control of artificial intelligence. He explains that humans have the choice to use these tools in the right way to improve society.
John Hopfield
Nobel Prize 2024. In 1982: artificial neural network.
Geoffrey Hinton
Nobel Prize 2024. In 1985: training method for neural networks.
Two of his students at the University of Toronto, Alex Krizhevsky and Ilya Sutskever, were the developers of ChatGPT.
Generative AI Use Case
Use case of Hanna Mergui, a PhD student working on medical imaging and its use with AI.
- Her background: https://youtu.be/zC8xdkTxuFc?si=KdQ_x-ijHsHlZ5Jr&t=181
Anna chose a career in computer science because she wanted something she could take abroad, and a field that is always evolving.
She first studied at the MathInfo university program, then went to Dauphine to study business computing. There, she took an introduction to AI course, and that was before the rise of ChatGPT and the AIs we know today.
Later, Anna joined Polytechnique through a bridge between universities and engineering schools. There, she completed a master's degree in AI, covering:
- the history of artificial intelligence,
- its various applications in imaging,
- video,
- and sound.
Finally, Anna wanted to apply her skills to a field close to her heart: medicine.
- Use case in medical imaging:
- Startup Sonio; fetal weight estimation
- PhD thesis on malformations detected during prenatal ultrasounds
- An AI trained with ultrasound images.
- AI needs thousands of data points and images to train.
- Generating fake images to train the AI.
- Generative AI models that are capable of creating these fake images. Two types of generative AI:
- GAN: generator and discriminator
- Diffusion models (DALL·E, MidJourney): deconstructing an image and rebuilding it using a prompt. Or AudioLM, MusicLM: generating sound and music
- Understanding the domain
- Ethics
- Data anonymization
- The doctor is not replaced — the machine helps with diagnosis. It’s like the doctor has an assistant. For example, the AI does not make any decisions. It provides lots of information and sees things (without getting tired…)
CREATE Generative AI Model
📌How do you train a generative AI model?
Training an AI model with images means teaching it to understand or generate images by giving it a large number of examples.
1. Define the goal
First, you need to know what you want the model to do:
| Goal | Example | Model type |
|---|---|---|
| Classification | "Is it a cat or a dog?" | CNN |
| Detection | "Where is the face in the image?" | R-CNN, YOLO |
| Generation | "Create an image of a cat" | GAN, Diffusion |
| Segmentation | "Color each pixel by object" | U-Net, Mask R-CNN |
2. Prepare the data
Gather images
- Or use your own images
Clean and organize
- Remove blurry or useless images
- Create one folder per class (e.g.: data/cats/, data/dogs/)
Resize and normalize
- Make all images the same size (e.g.: 224×224 pixels)
- Convert pixel values from [0–255] to [0–1] or [-1, 1] using a script (to fit AI algorithm needs)
3. Choose a model
The most common are convolutional neural networks (CNN) for image analysis:
- For beginners: ResNet, VGG, MobileNet
- For generation: GAN, UNet, Stable Diffusion
You can also use Transfer Learning (reusing a pre-trained model).
4. Train the model
Use a framework
- PyTorch
- TensorFlow / Keras
Simple example using Keras
📌Keras is a high-level open-source library in Python that allows you to easily build, train, and test AI models, especially neural networks.
Keras is used to create deep learning models.
You can do it on Google Colab (free, with GPU, fast parallel processing), for example.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
# Data preparation
datagen = ImageDataGenerator(rescale=1./255, validation_split=0.2)
train = datagen.flow_from_directory("data/", target_size=(224, 224), subset='training')
val = datagen.flow_from_directory("data/", target_size=(224, 224), subset='validation')
# Model creation
base_model = MobileNetV2(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
model = Sequential([
base_model,
GlobalAveragePooling2D(),
Dense(1, activation='sigmoid') # binary (cat/dog)
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(train, validation_data=val, epochs=5)5. Evaluate the model
- Error statistics
- Test with images the model has never seen before
6. Use or deploy
- Convert the model (.h5, .pt, .onnx)
- Deploy in a mobile app, website, or backend
Useful tools
| Need | Recommended tools |
|---|---|
| Image annotation | LabelImg, MakeSense.ai |
| Computer vision | OpenCV, torchvision |
| Cloud training | Google Colab, Kaggle, AWS SageMaker |