Base de données
cours de Julie Chaumard
INTRODUCTION
En anglais : database
Est ce que vous pouvez me dire ce que vous savez des base de données ?
Ecrire le vocabulaire utilisé dans les réponses au tableau. Donner le vocabulaire employé par le métier si besoin.
INVENTION DU MODÈLE RELATIONNEL
Le modèle relationnel des bases de données a été inventé par Edgar F. Codd, un informaticien britannique, en 1970. Codd travaillait chez IBM à l'époque, et il a publié un article fondamental intitulé "A Relational Model of Data for Large Shared Data Banks" dans le journal Communications of the ACM. Cet article a posé les bases théoriques du modèle relationnel, qui utilise des concepts de mathématiques, en particulier la théorie des ensembles et la logique des prédicats, pour organiser et manipuler les données.
Dans ses travaux du début des années 1970, il introduit la première forme normale (1NF), en insistant sur le fait qu’une relation doit être composée de valeurs atomiques (pas de colonnes contenant des listes ou des répétitions).
A quoi cela sert une DB
- A stocker des informations
- c’est quoi une information ?
C’est quoi les données ⇒ informations
- Donner des exemples
- Les données personnelles
- A les ranger et les classer
- A les retrouver facilement
- A manipuler les données :
- modifier
- supprimer
- rechercher
- partager (données ouvertes et API)
De quoi est constitué / fait / composé une BD
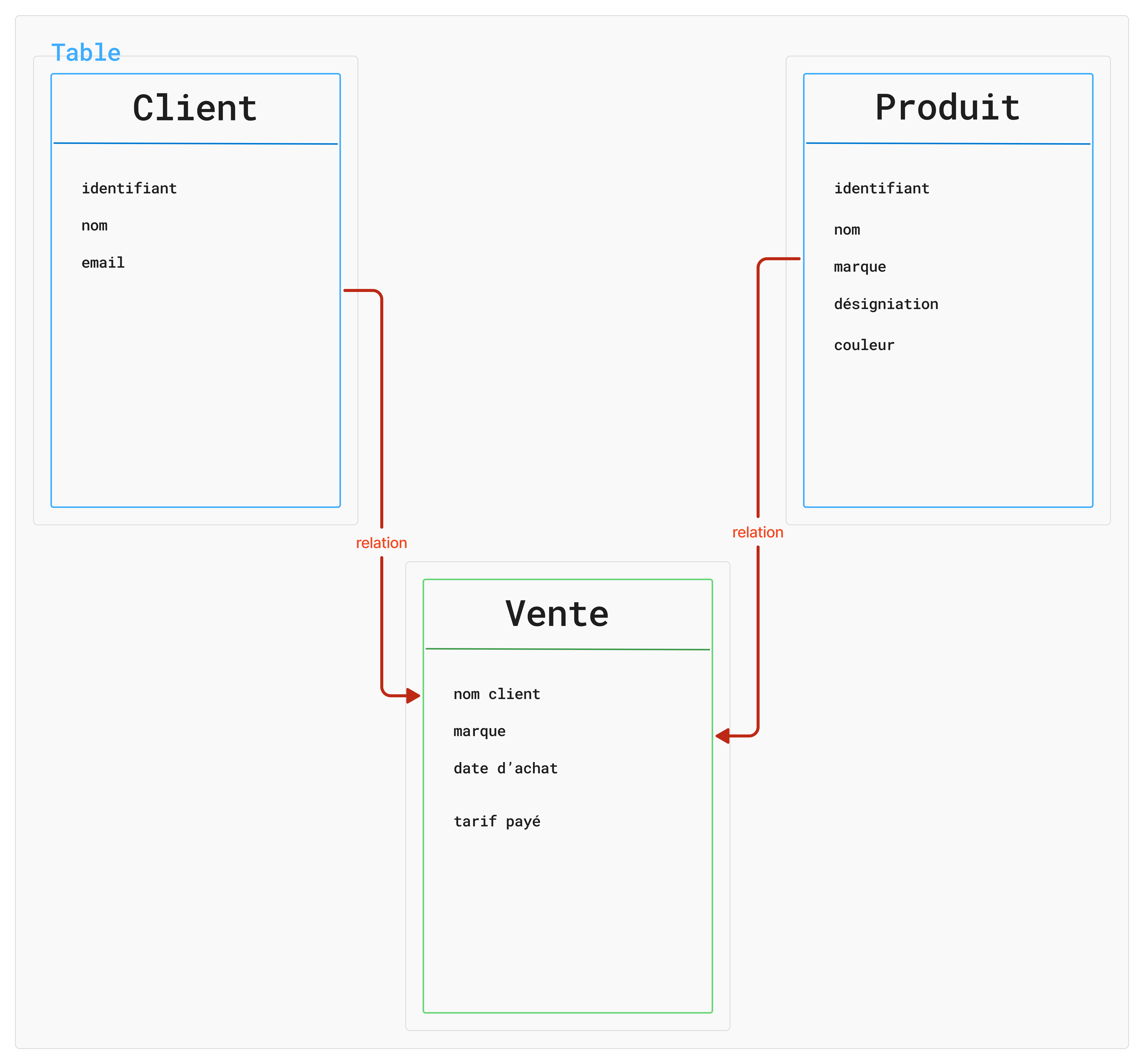
- nom de la base de données
- tables (qui représente une catégorie d’informations)
- des champs (renseignements) qui porte le nom de la données
- un identifiant unique pour chaque objet d’un table
- des relations : ce qui fait tout le pouvoir des bases de données relationnelles et l’intégrité des données
- L’intégrité des données est un principe fondamental qui garantit que les données stockées dans une base de données restent correctes, cohérentes, fiables et sécurisées.
- Elle empêche la corruption, la duplication ou la perte de données et assure que les informations restent exactes et exploitables.
- ✅ Respect du principe ACID :
- Atomicité : Une transaction est tout ou rien.
- Cohérence : Les données doivent rester valides après la transaction.
- Isolation : Les transactions concurrentes ne doivent pas interférer.
- Durabilité : Les données validées restent en base même après un crash.
- L’intégrité des données est principalement assurée par les contraintes et se divise en plusieurs types :
- 1️⃣ Intégrité d’entité (ou intégrité de clé primaire) :
- ✅ Assure que chaque ligne (enregistrement) dans une table est unique et identifiable.
- Comment ?
- Chaque table doit avoir une clé primaire (PRIMARY KEY).
- Une clé primaire ne peut pas être nulle (NOT NULL) et doit être unique.
- Comment ?
- ✅ Assure que chaque ligne (enregistrement) dans une table est unique et identifiable.
- 2️⃣ Intégrité référentielle :
- ✅ garantit que les relations entre les tables restent cohérentes.
- Comment ?
- Une clé étrangère (FOREIGN KEY) doit toujours pointer vers une clé primaire valide.
- Empêche la suppression d’une ligne référencée sans mise à jour des références.
- ➡ Si un utilisateur est supprimé, toutes ses commandes sont aussi supprimées (ON DELETE CASCADE).
- Comment ?
- ✅ Assure que les valeurs des colonnes sont valides et conformes aux types de données définis.
- Comment ?
- Définir des types de données (INT, VARCHAR(50), DATE, etc.).
- Utiliser des contraintes (CHECK, DEFAULT, NOT NULL) pour imposer des règles.
- Comment ?
- ✅ garantit que les relations entre les tables restent cohérentes.
- 4️⃣ Intégrité transactionnelle
- ✅ Assure que les données restent cohérentes même en cas d’échec d’une transaction.
- Comment ?
- Utilisation des transactions (BEGIN, COMMIT, ROLLBACK).
- Comment ?
- ✅ Assure que les données restent cohérentes même en cas d’échec d’une transaction.
BEGIN; UPDATE Comptes SET solde = solde - 100 WHERE id = 1; UPDATE Comptes SET solde = solde + 100 WHERE id = 2; COMMIT; -- Valide les changements -- ou ROLLBACK; -- Annule tout si une erreur survient - 1️⃣ Intégrité d’entité (ou intégrité de clé primaire) :
‼️ Data Science - Big Data
- Des exemples d’usage de data analyse : https://www.tableau.com/fr-fr/learn/articles/best-beautiful-data-visualization-examples
- un exemple en particulier : les dialogues des films Disney : https://pudding.cool/2017/03/film-dialogue/
- Une série Arte sur la data science : https://www.arte.tv/fr/videos/081077-005-A/data-science-vs-fake/
- Les données dans le sport, le baseball : https://www.baseball-reference.com/teams/PHI/2024.shtml
- initié par le film Moneyball
Règlementation
- On visite le site de la CNIL ⇒ on cherche la réglementation sur les données et les bases de données
- les droits, pour qui ?, comment ?
- les devoirs, par qui ?, comment ?
RGPD & CNIL
- Protection contre la vente de données, le vol de données
- où sont stockées les informations ⇒ obligation de tracabilité
- RGPD aux US en chine ??
Normes comme PCIDSS :
- locaux protégé par l’identification par empreinte
- pas de quoi écrire à disposition
Métiers et Softskills nécessaires
- rigoureux, méthode
- capacité d’analyse
- une connaissance méthodologique,
- une certaine capacité d'abstraction,
- la faculté de comprendre la réalité d'autrui, empathie
Aller sur le site onisep ou france compétence pour voir les métiers (data analyst : https://www.francecompetences.fr/recherche/rncp/37429/)
- DBA Administrateur de Bases de Données (DBA - Database Administrator). Le DBA est responsable de la conception, l’installation, la maintenance et l’optimisation des bases de données d’une entreprise. Ses principales missions incluent :
- Concevoir et gérer les bases de données (modélisation, architecture).
- Assurer la sécurité des données (gestion des accès, sauvegardes, récupération).
- Optimiser les performances (indexation, requêtes SQL optimisées).
- Gérer la disponibilité et l’intégrité des données (assurer la continuité du service).
- Effectuer des mises à jour et des migrations (mise à jour des versions de bases de données, évolutions technologiques).
- Ingénieur Data (Data Engineer) → Conçoit et gère les pipelines de données (ETL, Big Data).
- Développeur SQL → Spécialisé dans l’écriture de requêtes et la gestion de bases relationnelles.
- Architecte Data → Définit l’architecture globale des bases et des flux de données.
- Analyste de données (Data Analyst) → Exploite les données pour produire des analyses stratégiques.
- Scientifique des données (Data Scientist) → Utilise l’IA et le Machine Learning sur les bases de données.
Requêtes SQL
On va interroger la base de données pour récupérer les informations.
Le langage pour faire des requêtes auprès d’une base de données relationnelle s’appelle le SQL.
- Par exemple avec Spotify : on demande la liste des groupes de musique avec la condition qu’ils chantent en espagnol.
Un outil pour apprendre les requêtes SQL : https://www.sql-practice.com/
API
Une API n’est pas réservée au NoSQL. Elle est juste une couche intermédiaire entre ton appli et ta base, peu importe que ce soit du SQL ou du NoSQL.
Exemple concret avec SQL
Supposons que tu as une base MySQL avec 3 tables :
- Etudiants(id, nom)
- Cours(id, nom)
- Inscriptions(etudiant_id, cours_id)
Tu peux créer une API (par exemple en Node.js + Express, ou PHP/Laravel, ou Python/FastAPI) qui expose des routes comme :
- GET /etudiants → retourne la liste des étudiants (SELECT * FROM Etudiants)
- GET /etudiants/1 → retourne Julie avec ses cours (jointure SQL)
- POST /etudiants → insère un nouvel étudiant (INSERT INTO)
- PUT /etudiants/1 → met à jour un étudiant (UPDATE)
- DELETE /etudiants/1 → supprime un étudiant (DELETE)
C’est l’API qui traduit tes appels HTTP en requêtes SQL vers ta base relationnelle.
Pourquoi on fait ça ?
- Pour sécuriser (les clients ne touchent pas directement la BDD).
- Pour contrôler ce qui est exposé (par exemple, tu ne montres pas les mails/numéros de téléphone à tout le monde).
- Pour uniformiser : ton appli web, ton appli mobile, ton futur service tiers → tous passent par la même API.
On peut créer une API REST ou GraphQL sur une base SQL (MySQL, PostgreSQL, SQL Server, …)
Données ouvertes
Par exemple Wikipedia ou BNF
Interrogation de wikipedia avec SPARQL en SQL
Normalisation
La normalisation en bases de données est une méthode pour organiser les tables et leurs relations afin d’éviter les incohérences et les redondances.
L’idée est simple :
- tu veux stocker une donnée une seule fois,
- et être sûr qu’elle reste cohérente même si tu la modifies,
- tout en gardant la base flexible pour les requêtes.
Exemple rapide
Si tu as une table Étudiants avec :
id | nom | cours_suivis
1 | Julie | Math, Info
2 | Karim | Info
Ici, cours_suivis casse un principe : une cellule contient plusieurs valeurs.
→ Pas normalisé.
En normalisant, tu sépares en plusieurs tables :
- Étudiants(id, nom)
- Cours(id, nom)
- Inscription(etudiant_id, cours_id)
Ça devient plus clair, plus souple, et ça évite de réécrire “Info” partout.
Les étapes (formes normales)
- 1NF : chaque colonne contient des valeurs atomiques (pas de listes ou champs multiples).
- 2NF : pas de dépendances partielles (chaque colonne doit dépendre de toute la clé primaire).
- 3NF : pas de dépendances transitives (les colonnes doivent dépendre directement de la clé, pas d’une autre colonne).
- BCNF et suivantes : raffinements pour des cas plus subtils.
La normalisation, c’est “nettoyer” le schéma de ta base pour limiter les anomalies d’insertion, de mise à jour et de suppression.
Exemple
Table non normalisée :
Etudiants
| id | nom | cours | prof |
|---|---|---|---|
| 1 | Julie | Math | Dupont |
| 2 | Karim | Info | Martin |
| 3 | Sam | Math | Dupont |
1. Anomalie d’insertion
Si tu veux ajouter un nouveau cours “Physique” avec son prof “Durand”, mais qu’aucun étudiant ne le suit encore, tu ne peux pas l’inscrire dans cette table.
Il faut attendre qu’un étudiant prenne le cours pour pouvoir l’ajouter.
2. Anomalie de mise à jour
Si le prof “Dupont” change d’adresse mail ou de nom, il faut mettre à jour toutes les lignes où il apparaît.
Si tu en oublies une, tu crées une incohérence.
3. Anomalie de suppression
Si tu supprimes l’étudiant “Sam”, tu perds aussi l’information que le cours “Math” est donné par “Dupont”.
Donc une simple suppression fait disparaître des données utiles.
Solution : normaliser
Tu éclates la table en plusieurs :
- Etudiants(id, nom)
- Cours(id, nom, prof)
- Inscriptions(etudiant_id, cours_id)
Et là :
- Tu peux ajouter “Physique” dans Cours sans attendre un étudiant.
- Si “Dupont” change, tu modifies une seule ligne.
- Supprimer “Sam” n’efface pas le cours “Math”.
MCD / MLD CONCEVOIR LA BASE DE DONNÉES DE SPOTIFY
Nous allons concevoir l’application Boosfy, basé sur le modèle de Spotify
Application pour écouter de la musique dédiée à la génération Alpha
Règles de gestion
- Un utilisateur peut créer plusieurs playlists, et une playlist est créé par 1 et 1 seul utilisateur : Relation un-à-plusieurs entre
UsersetPlaylists.
- Une playlist peut contenir plusieurs chansons et une chanson peut appartenir à plusieurs playlists : Relation plusieurs-à-plusieurs entre
PlaylistsetSongs, gérée par la table intermédiairePlaylist_Songs.
- Un artiste peut avoir plusieurs albums : Relation un-à-plusieurs entre
ArtistsetAlbums.
- Un album peut contenir plusieurs chansons, et une chanson appartient à un seul album : Relation un-à-plusieurs entre
AlbumsetSongs.
- Un utilisateur peut écouter plusieurs chansons : Relation un-à-plusieurs entre
UsersetListening_History.
- Faire un classement des musiques les plus écoutés
- Les playlist peuvent se partager
- Proposer un minuteur pour stopper le player (en cas d’endormissement par ex)
- Proposer un contrôle parental pour les moins de 16 ans
- Tarifs
- abonnement mensuel 6,99€
- abonnement annuel 69,99€
- Faire un minuteur
- controle parental pour les moins de 16 ans
Dictionnaire des données
- SON : titre, durée, brevet (c’est la chanson qui se nomme “son” en langage de la génération Alpha)
- ALBUM : titre, type
- ARTISTE : nom
- CRÉATEUR DE PODCAST : nom
- PODCAT : titre
- CONSO : nom, CB, e-mail, tel (c’est l’utilisateur qui se nomme “conso” en langage de la génération Alpha)
- Playlist : nom
Le modèle MCD
Modèle créé en classe en février 2025
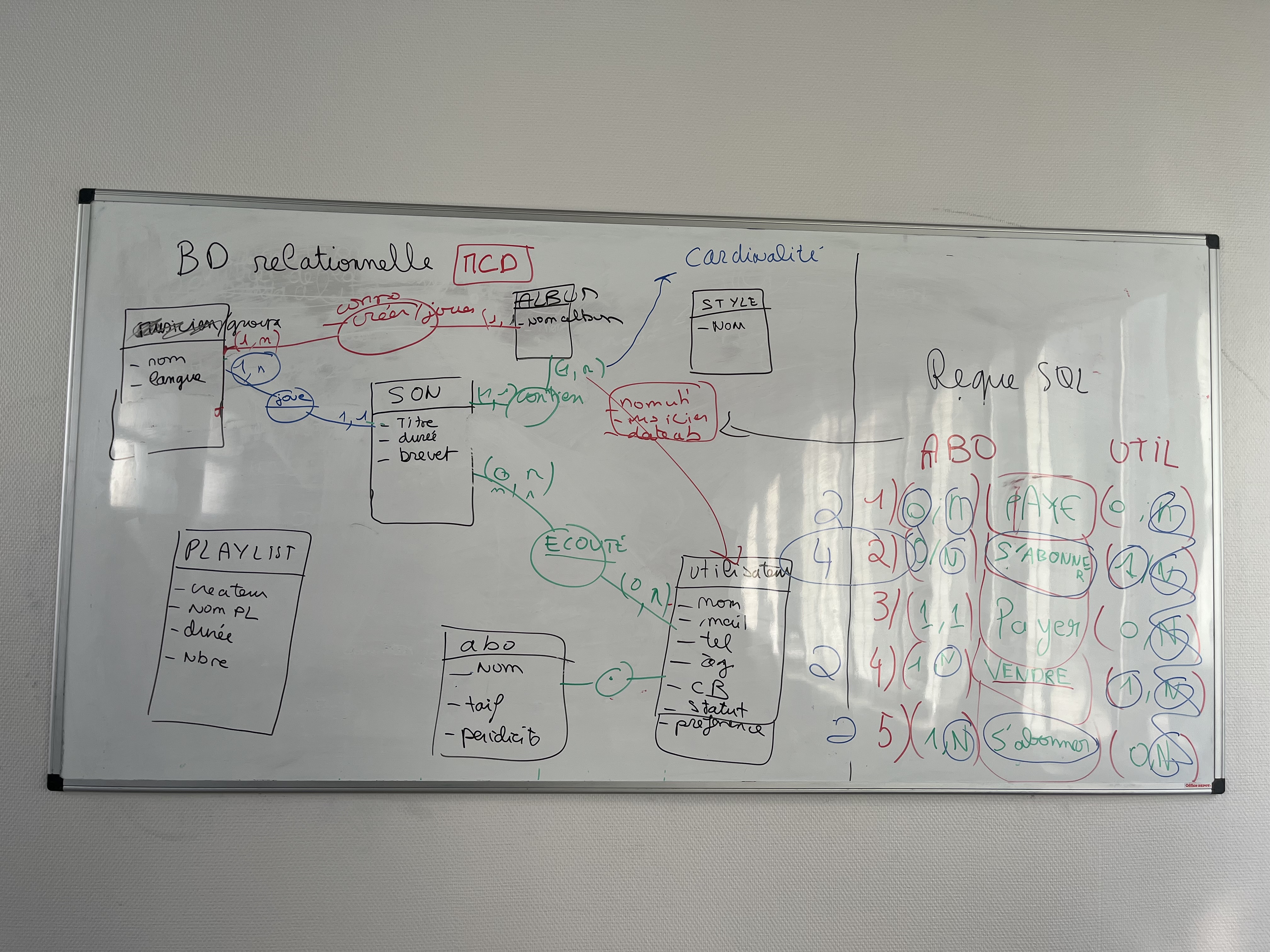
Le MCD (modèle conceptuel des données) contient des entités et leurs propriétés ainsi que des relations caractérisée entre les entités.
Construite un MCD en ligne https://www.mocodo.net/
MCD POUR MOCODO
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% %
% BOSSFY %
% %
% Nous allons concevoir l’application Boosfy, basé sur le modèle de Spotify %
% entité, association, attribut, identifiant, cardinalité, patte, rôle. %
% %
% Julie Chaumard pour Parisweb.art %
% %
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
ÉCOUTER, 1N CONSO, 0N SON: qté écouté [INTEGER]
CONSO: num. conso [VARCHAR(8)], nom conso [VARCHAR(255)], CB conso [], e-mail conso [], telephone conso [VARCHAR(20)],
PODCASTÉ, 1N CONSO, 0N PODCAST: qté écouté [INTEGER]
PODCAST: num. podcast [VARCHAR(8)], titre podcast [], durée podcast []
DIFFUSE, 1N PODCAST, 11 PODCASTEUR: quantité [INTEGER]
SON: num. son [VARCHAR(8)], titre son [], durée son [], brevet son []
RANGE, 1N CONSO, 0N PLAYLIST, 1N SON: qté écouté [INTEGER]
:
:
PODCASTEUR: num. podcasteur [VARCHAR(8)], nom podcasteur [VARCHAR(255)]
CONTIENT, 11 SON, 1N ALBUM
PLAYLIST: num. playlist [VARCHAR(8)], titre playlist [], durée playlist []
:
:
:
ALBUM: num. album [VARCHAR(8)], titre album [], type album []
PRODUIT, 1N ALBUM, 1N ARTISTE: quantité [INTEGER]
ARTISTE: num. artiste [VARCHAR(8)], nom artiste [VARCHAR(255)], label artiste []
:
:
- Les éléments se positionne sur la ligne et un retour ligne vaut un retour à la ligne pour les éléments suivants.
- Pour positionner les éléments en décalage sous un éléments du dessi-us ajouter deux points “:”

EXERCICE
- Ajouter la gestion de l’abonnement
- Donner la possibilité de mettre plusieurs tag au son, à l’album et au podcast (le tag au son et à l’album sont les mêmes)
Passage vers le MLD
⚠ Différence entre 1,N et 1,1
| Cardinalité | Où va la clé étrangère ? | Contrainte supplémentaire |
|---|---|---|
| 1,N | Dans la table du côté N | Aucune |
| 1,1 | Dans l’une des deux tables | UNIQUE sur la clé étrangère |
- N,N 👉 on créé une table qui contient les 2 clés
- 1,N 👉 La clé étrangère est dans la table du côté N.
- 1,1 👉 La clé étrangère peut aller dans l’une des tables, avec une contrainte UNIQUE.
Règles pour une relation (N,N)
| Étape | Action |
| 1 | Créer une table d’association avec les clés étrangères des deux entités |
| 2 | Définir une clé primaire composite (clé_1, clé_2) |
| 3 | Ajouter les contraintes de clé étrangère pour garantir l’intégrité |
| 4 (optionnel) | Ajouter des attributs supplémentaires si nécessaire |
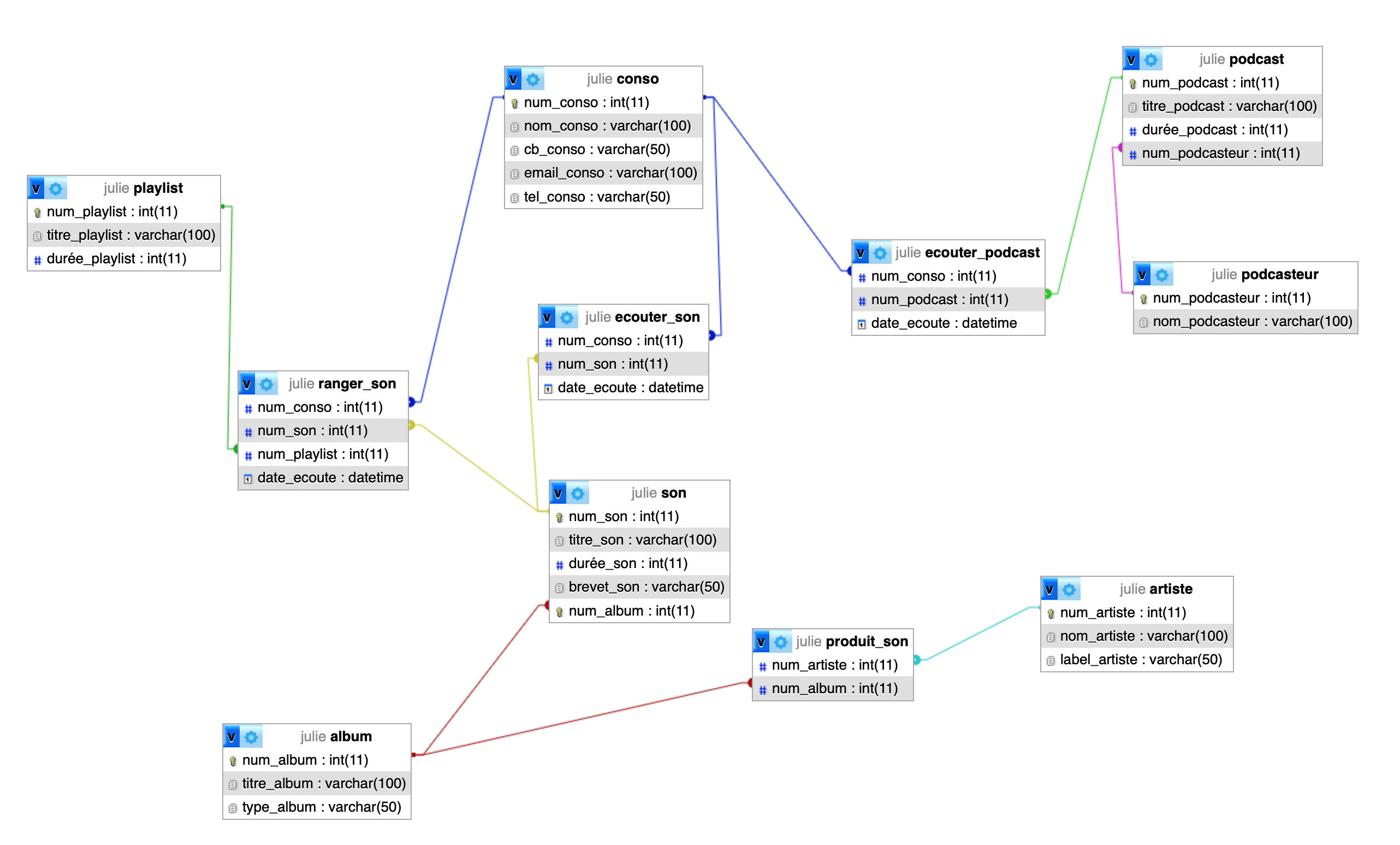
Le modèle MLD

SQL
Le modèle MPD
Le modèle physique des données reprend MLD en y ajoutant l’indication du format de chaque propriété
SQL Création des tables
-- phpMyAdmin SQL Dump
-- version 6.0.0-dev
-- https://www.phpmyadmin.net/
--
-- Hôte : 192.168.30.23
-- Généré le : dim. 03 Nov. 2024 à 21:34
-- Version du serveur : 8.0.18
-- Version de PHP : 8.2.20
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
START TRANSACTION;
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
--
-- Base de données : `julie`
--
-- --------------------------------------------------------
--
-- Structure de la table `album`
--
CREATE TABLE `album` (
`num_album` int(11) NOT NULL,
`titre_album` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL,
`type_album` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
--
-- Déchargement des données de la table `album`
--
-- Données pour la table album avec des exemples d'albums réels
INSERT INTO `album` (`num_album`, `titre_album`, `type_album`) VALUES
(1, 'Thriller', 'Pop'),
(2, 'The Dark Side of the Moon', 'Rock'),
(3, 'Back to Black', 'Soul'),
(4, 'Rumours', 'Rock'),
(5, 'Kind of Blue', 'Jazz'),
(6, 'Abbey Road', 'Rock'),
(7, 'The Eminem Show', 'Hip-hop'),
(8, 'Nevermind', 'Grunge'),
(9, '21', 'Pop'),
(10, 'Hotel California', 'Rock'),
(11, 'Lemonade', 'Pop'),
(12, 'A Night at the Opera', 'Rock'),
(13, 'Random Access Memories', 'Electro'),
(14, 'To Pimp a Butterfly', 'Hip-hop'),
(15, 'The Wall', 'Rock'),
(16, '1989', 'Pop'),
(17, 'In the Wee Small Hours', 'Jazz'),
(18, 'Led Zeppelin IV', 'Rock'),
(19, 'Songs in the Key of Life', 'Soul'),
(20, 'DAMN.', 'Hip-hop');
-- --------------------------------------------------------
--
-- Structure de la table `artiste`
--
CREATE TABLE `artiste` (
`num_artiste` int(11) NOT NULL,
`nom_artiste` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL,
`label_artiste` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
--
-- Déchargement des données de la table `artiste`
--
-- Données pour la table artiste avec des exemples d'artistes réels
INSERT INTO `artiste` (`num_artiste`, `nom_artiste`, `label_artiste`) VALUES
(1, 'Michael Jackson', 'Epic'),
(2, 'Pink Floyd', 'Harvest'),
(3, 'Amy Winehouse', 'Island'),
(4, 'Fleetwood Mac', 'Warner Bros.'),
(5, 'Miles Davis', 'Columbia'),
(6, 'The Beatles', 'Apple'),
(7, 'Eminem', 'Aftermath'),
(8, 'Nirvana', 'DGC'),
(9, 'Adele', 'XL Recordings'),
(10, 'Eagles', 'Asylum'),
(11, 'Beyoncé', 'Parkwood'),
(12, 'Queen', 'EMI'),
(13, 'Daft Punk', 'Columbia'),
(14, 'Kendrick Lamar', 'Top Dawg'),
(15, 'Led Zeppelin', 'Atlantic'),
(16, 'Taylor Swift', 'Big Machine'),
(17, 'Frank Sinatra', 'Capitol'),
(18, 'Stevie Wonder', 'Motown'),
(19, 'Jay-Z', 'Roc-A-Fella'),
(20, 'The Rolling Stones', 'Rolling Stones');
-- --------------------------------------------------------
--
-- Structure de la table `conso`
--
CREATE TABLE `conso` (
`num_conso` int(11) NOT NULL,
`nom_conso` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL,
`cb_conso` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL,
`email_conso` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL,
`tel_conso` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
--
-- Déchargement des données de la table `conso`
--
INSERT INTO `conso` (`num_conso`, `nom_conso`, `cb_conso`, `email_conso`, `tel_conso`) VALUES
(1, 'Alice Martin', 'CB12345', 'alice@example.com', '0123456789'),
(2, 'Bob Robert', 'CB67890', 'bob@example.com', '0987654321'),
(3, 'Clara Dubois', 'CB34567', 'clara@example.com', '0145236879'),
(4, 'David Lefevre', 'CB45678', 'david@example.com', '0654321876'),
(5, 'Eva Martin', 'CB56789', 'eva@example.com', '0623481795'),
(6, 'Frank Simon', 'CB67891', 'frank@example.com', '0734125689'),
(7, 'George Emile', 'CB78912', 'george@example.com', '0781234590'),
(8, 'Hannah Scott', 'CB89123', 'hannah@example.com', '0678912345'),
(9, 'Iris White', 'CB91234', 'iris@example.com', '0657812349'),
(10, 'Jack Green', 'CB23456', 'jack@example.com', '0723416589'),
(11, 'Karen Black', 'CB34568', 'karen@example.com', '0634781529'),
(12, 'Leo King', 'CB45679', 'leo@example.com', '0765432189'),
(13, 'Mona Brown', 'CB56781', 'mona@example.com', '0689123547'),
(14, 'Nina Wilson', 'CB67892', 'nina@example.com', '0743216589'),
(15, 'Oscar Reed', 'CB78913', 'oscar@example.com', '0675341289'),
(16, 'Paul Grey', 'CB89124', 'paul@example.com', '0721346578'),
(17, 'Quinn Hill', 'CB91235', 'quinn@example.com', '0624587139'),
(18, 'Ray Fox', 'CB12356', 'ray@example.com', '0745618239'),
(19, 'Sophia Lane', 'CB23457', 'sophia@example.com', '0654789132'),
(20, 'Tom Bright', 'CB34569', 'tom@example.com', '0732146895');
-- --------------------------------------------------------
--
-- Structure de la table `ecouter_podcast`
--
CREATE TABLE `ecouter_podcast` (
`num_conso` int(11) NOT NULL,
`num_podcast` int(11) NOT NULL,
`date_ecoute` datetime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
--
-- Déchargement des données de la table `ecouter_podcast`
--
INSERT INTO `ecouter_podcast` (`num_conso`, `num_podcast`, `date_ecoute`) VALUES
(1, 1, '2024-11-01 10:30:00'),
(2, 2, '2024-11-02 15:45:00'),
(3, 3, '2024-11-03 18:00:00'),
(4, 4, '2024-11-04 20:15:00'),
(5, 5, '2024-11-05 21:30:00'),
(6, 6, '2024-11-06 22:45:00'),
(7, 7, '2024-11-07 23:00:00'),
(8, 8, '2024-11-08 09:15:00'),
(9, 9, '2024-11-09 11:30:00'),
(10, 10, '2024-11-10 13:45:00'),
(11, 11, '2024-11-11 15:00:00'),
(12, 12, '2024-11-12 16:15:00'),
(13, 13, '2024-11-13 17:30:00'),
(14, 14, '2024-11-14 18:45:00'),
(15, 15, '2024-11-15 19:00:00'),
(16, 16, '2024-11-16 20:15:00'),
(17, 17, '2024-11-17 21:30:00'),
(18, 18, '2024-11-18 22:45:00'),
(19, 19, '2024-11-19 23:00:00'),
(20, 20, '2024-11-20 09:15:00');
-- --------------------------------------------------------
--
-- Structure de la table `ecouter_son`
--
CREATE TABLE `ecouter_son` (
`num_conso` int(11) NOT NULL,
`num_son` int(11) NOT NULL,
`date_ecoute` datetime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
-- Données pour la table ecouter_son avec des exemples d'écoutes de chansons
INSERT INTO `ecouter_son` (`num_conso`, `num_son`, `date_ecoute`) VALUES
(1, 1, '2024-10-01 10:00:00'),
(2, 2, '2024-10-01 10:30:00'),
(3, 3, '2024-09-01 11:00:00'),
(4, 4, '2024-08-01 11:30:00'),
(5, 5, '2024-08-01 12:00:00'),
(6, 6, '2024-08-01 12:30:00'),
(7, 7, '2024-11-01 13:00:00'),
(8, 8, '2024-11-02 13:30:00'),
(9, 9, '2024-11-01 14:00:00'),
(10, 10, '2024-10-02 14:30:00'),
(11, 11, '2024-10-02 15:00:00'),
(12, 12, '2024-10-02 15:30:00'),
(13, 13, '2024-11-01 16:00:00'),
(14, 14, '2024-11-01 16:30:00'),
(15, 15, '2024-10-12 17:00:00'),
(16, 16, '2024-10-12 17:30:00'),
(17, 17, '2024-10-12 18:00:00'),
(18, 18, '2024-08-11 18:30:00'),
(19, 19, '2024-09-21 19:00:00'),
(20, 20, '2024-09-21 19:30:00');
-- --------------------------------------------------------
--
-- Structure de la table `playlist`
--
CREATE TABLE `playlist` (
`num_playlist` int(11) NOT NULL,
`titre_playlist` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL,
`durée_playlist` int(11) NOT NULL COMMENT 'secondes'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
--
-- Déchargement des données de la table `playlist`
--
INSERT INTO `playlist` (`num_playlist`, `titre_playlist`, `durée_playlist`) VALUES
(1, 'Playlist Relax', 3000),
(2, 'Playlist Workout', 3200),
(3, 'Playlist Party', 3600),
(4, 'Playlist Study', 1800),
(5, 'Playlist Chill', 2500),
(6, 'Playlist Jazz', 2700),
(7, 'Playlist Rock', 2400),
(8, 'Playlist Indie', 2200),
(9, 'Playlist Electro', 3100),
(10, 'Playlist Pop', 2800),
(11, 'Playlist Focus', 2000),
(12, 'Playlist Blues', 2600),
(13, 'Playlist Classical', 3400),
(14, 'Playlist Summer', 2900),
(15, 'Playlist Travel', 3000),
(16, 'Playlist Hits', 3700),
(17, 'Playlist Love', 3300),
(18, 'Playlist Dance', 3100),
(19, 'Playlist Winter', 2600),
(20, 'Playlist RnB', 2800);
-- --------------------------------------------------------
--
-- Structure de la table `podcast`
--
CREATE TABLE `podcast` (
`num_podcast` int(11) NOT NULL,
`titre_podcast` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL,
`durée_podcast` int(11) NOT NULL COMMENT 'secondes',
`num_podcasteur` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
--
-- Déchargement des données de la table `podcast`
--
INSERT INTO `podcast` (`num_podcast`, `titre_podcast`, `durée_podcast`, `num_podcasteur`) VALUES
(1, 'Découverte Scientifique', 1200, 1),
(2, 'Tech Actu', 1800, 2),
(3, 'Exploration de l\'Univers', 2400, 3),
(4, 'Histoire de la Physique', 3600, 4),
(5, 'Mathématiques Modernes', 1500, 5),
(6, 'Biologie Cellulaire', 3000, 6),
(7, 'Algorithmes et IA', 2700, 7),
(8, 'Philosophie des Sciences', 2100, 8),
(9, 'Sécurité Informatique', 1950, 9),
(10, 'Chimie Organique', 2850, 10),
(11, 'Ingénierie Aérospatiale', 2600, 11),
(12, 'Géophysique', 2200, 12),
(13, 'Neurosciences', 2550, 13),
(14, 'Astronomie', 2300, 14),
(15, 'Ingénierie Robotique', 2500, 15),
(16, 'Physique Quantique', 2800, 16),
(17, 'Climatologie', 3200, 17),
(18, 'Chimie des Matériaux', 2150, 18),
(19, 'Physiologie Humaine', 2650, 19),
(20, 'Médecine Génétique', 2900, 20);
-- --------------------------------------------------------
--
-- Structure de la table `podcasteur`
--
CREATE TABLE `podcasteur` (
`num_podcasteur` int(11) NOT NULL,
`nom_podcasteur` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
--
-- Déchargement des données de la table `podcasteur`
--
INSERT INTO `podcasteur` (`num_podcasteur`, `nom_podcasteur`) VALUES
(1, 'Jean Dupont'),
(2, 'Marie Curie'),
(3, 'Thomas Edison'),
(4, 'Sophie Germain'),
(5, 'Albert Einstein'),
(6, 'Nikola Tesla'),
(7, 'Isaac Newton'),
(8, 'Ada Lovelace'),
(9, 'Grace Hopper'),
(10, 'Alan Turing'),
(11, 'Rosalind Franklin'),
(12, 'Enrico Fermi'),
(13, 'Max Planck'),
(14, 'Galileo Galilei'),
(15, 'Leonardo da Vinci'),
(16, 'Stephen Hawking'),
(17, 'Richard Feynman'),
(18, 'Carl Sagan'),
(19, 'Katherine Johnson'),
(20, 'James Clerk Maxwell');
-- --------------------------------------------------------
--
-- Structure de la table `produit_son`
--
CREATE TABLE `produit_son` (
`num_artiste` int(11) NOT NULL,
`num_album` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
--
-- Déchargement des données de la table `produit_son`
--
INSERT INTO `produit_son` (`num_artiste`, `num_album`) VALUES
(1, 1),
(2, 2),
(3, 3),
(4, 4),
(5, 5),
(6, 6),
(7, 7),
(8, 8),
(9, 9),
(10, 10),
(11, 11),
(12, 12),
(13, 13),
(14, 14),
(15, 15),
(16, 16),
(17, 17),
(18, 18),
(19, 19),
(20, 20);
-- --------------------------------------------------------
--
-- Structure de la table `ranger_son`
--
CREATE TABLE `ranger_son` (
`num_conso` int(11) NOT NULL,
`num_son` int(11) NOT NULL,
`num_playlist` int(11) NOT NULL,
`date_ecoute` datetime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
-- Exemples pour la table ranger_son avec 20 entrées
INSERT INTO `ranger_son` (`num_conso`, `num_son`, `num_playlist`, `date_ecoute`) VALUES
(1, 1, 1, '2024-11-01 10:00:00'), -- Alice Martin a ajouté "Chanson 1" à "Playlist Relax"
(2, 3, 2, '2024-11-01 11:15:00'), -- Bob Robert a ajouté "Chanson 3" à "Playlist Workout"
(3, 5, 3, '2024-11-01 12:30:00'), -- Clara Dubois a ajouté "Chanson 5" à "Playlist Party"
(4, 7, 4, '2024-11-01 13:45:00'), -- David Lefevre a ajouté "Chanson 7" à "Playlist Study"
(5, 9, 5, '2024-11-01 15:00:00'), -- Eva Martin a ajouté "Chanson 9" à "Playlist Chill"
(6, 11, 6, '2024-11-01 16:15:00'), -- Frank Simon a ajouté "Chanson 11" à "Playlist Jazz"
(7, 13, 7, '2024-11-01 17:30:00'), -- George Emile a ajouté "Chanson 13" à "Playlist Rock"
(8, 15, 8, '2024-11-01 18:45:00'), -- Hannah Scott a ajouté "Chanson 15" à "Playlist Indie"
(9, 17, 9, '2024-11-01 20:00:00'), -- Iris White a ajouté "Chanson 17" à "Playlist Electro"
(10, 19, 10, '2024-11-01 21:15:00'), -- Jack Green a ajouté "Chanson 19" à "Playlist Pop"
(11, 2, 1, '2024-11-02 10:00:00'), -- Karen Black a ajouté "Chanson 2" à "Playlist Relax"
(12, 4, 2, '2024-11-02 11:15:00'), -- Leo King a ajouté "Chanson 4" à "Playlist Workout"
(13, 6, 3, '2024-11-02 12:30:00'), -- Mona Brown a ajouté "Chanson 6" à "Playlist Party"
(14, 8, 4, '2024-11-02 13:45:00'), -- Nina Wilson a ajouté "Chanson 8" à "Playlist Study"
(15, 10, 5, '2024-11-02 15:00:00'), -- Oscar Reed a ajouté "Chanson 10" à "Playlist Chill"
(16, 12, 6, '2024-11-02 16:15:00'), -- Paul Grey a ajouté "Chanson 12" à "Playlist Jazz"
(17, 14, 7, '2024-11-02 17:30:00'), -- Quinn Hill a ajouté "Chanson 14" à "Playlist Rock"
(18, 16, 8, '2024-11-02 18:45:00'), -- Ray Fox a ajouté "Chanson 16" à "Playlist Indie"
(19, 18, 9, '2024-11-02 20:00:00'), -- Sophia Lane a ajouté "Chanson 18" à "Playlist Electro"
(20, 20, 10, '2024-11-02 21:15:00'); -- Tom Bright a ajouté "Chanson 20" à "Playlist Pop"
-- --------------------------------------------------------
--
-- Structure de la table `son`
--
CREATE TABLE `son` (
`num_son` int(11) NOT NULL,
`titre_son` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL,
`durée_son` int(11) NOT NULL COMMENT 'secondes',
`brevet_son` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL,
`num_album` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
--
-- Déchargement des données de la table `son`
--
-- Données pour la table son avec des exemples de chansons réelles
INSERT INTO `son` (`num_son`, `titre_son`, `durée_son`, `brevet_son`, `num_album`) VALUES
(1, 'Billie Jean', 293, 'BREV001', 1),
(2, 'Time', 413, 'BREV002', 2),
(3, 'Rehab', 211, 'BREV003', 3),
(4, 'Go Your Own Way', 231, 'BREV004', 4),
(5, 'So What', 561, 'BREV005', 5),
(6, 'Come Together', 259, 'BREV006', 6),
(7, 'Without Me', 290, 'BREV007', 7),
(8, 'Smells Like Teen Spirit', 301, 'BREV008', 8),
(9, 'Rolling in the Deep', 228, 'BREV009', 9),
(10, 'Hotel California', 391, 'BREV010', 10),
(11, 'Formation', 233, 'BREV011', 11),
(12, 'Bohemian Rhapsody', 355, 'BREV012', 12),
(13, 'Get Lucky', 369, 'BREV013', 13),
(14, 'Alright', 233, 'BREV014', 14),
(15, 'Stairway to Heaven', 482, 'BREV015', 15),
(16, 'Shake It Off', 242, 'BREV016', 16),
(17, 'In the Wee Small Hours of the Morning', 177, 'BREV017', 17),
(18, 'Black Dog', 296, 'BREV018', 18),
(19, 'Sir Duke', 230, 'BREV019', 19),
(20, 'DNA.', 185, 'BREV020', 20);
--
-- Index pour les tables déchargées
--
--
-- Index pour la table `album`
--
ALTER TABLE `album`
ADD PRIMARY KEY (`num_album`);
--
-- Index pour la table `artiste`
--
ALTER TABLE `artiste`
ADD PRIMARY KEY (`num_artiste`);
--
-- Index pour la table `conso`
--
ALTER TABLE `conso`
ADD PRIMARY KEY (`num_conso`);
--
-- Index pour la table `ecouter_podcast`
--
ALTER TABLE `ecouter_podcast`
ADD PRIMARY KEY (`num_conso`,`num_podcast`),
ADD KEY `num_podcast` (`num_podcast`),
ADD KEY `num_conso` (`num_conso`);
--
-- Index pour la table `ecouter_son`
--
ALTER TABLE `ecouter_son`
ADD PRIMARY KEY (`num_conso`,`num_son`),
ADD KEY `num_son` (`num_son`),
ADD KEY `num_conso` (`num_conso`);
--
-- Index pour la table `playlist`
--
ALTER TABLE `playlist`
ADD PRIMARY KEY (`num_playlist`);
--
-- Index pour la table `podcast`
--
ALTER TABLE `podcast`
ADD PRIMARY KEY (`num_podcast`),
ADD KEY `num_podcasteur` (`num_podcasteur`);
--
-- Index pour la table `podcasteur`
--
ALTER TABLE `podcasteur`
ADD PRIMARY KEY (`num_podcasteur`);
--
-- Index pour la table `produit_son`
--
ALTER TABLE `produit_son`
ADD PRIMARY KEY (`num_artiste`,`num_album`),
ADD KEY `num_artiste` (`num_artiste`),
ADD KEY `num_album` (`num_album`);
--
-- Index pour la table `ranger_son`
--
ALTER TABLE `ranger_son`
ADD PRIMARY KEY (`num_conso`,`num_son`,`num_playlist`),
ADD KEY `num_playlist` (`num_playlist`),
ADD KEY `num_son` (`num_son`),
ADD KEY `num_conso` (`num_conso`);
--
-- Index pour la table `son`
--
ALTER TABLE `son`
ADD PRIMARY KEY (`num_son`),
ADD UNIQUE KEY `num_album` (`num_album`);
--
-- AUTO_INCREMENT pour les tables déchargées
--
--
-- AUTO_INCREMENT pour la table `album`
--
ALTER TABLE `album`
MODIFY `num_album` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=21;
--
-- AUTO_INCREMENT pour la table `artiste`
--
ALTER TABLE `artiste`
MODIFY `num_artiste` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=21;
--
-- AUTO_INCREMENT pour la table `conso`
--
ALTER TABLE `conso`
MODIFY `num_conso` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=21;
--
-- AUTO_INCREMENT pour la table `playlist`
--
ALTER TABLE `playlist`
MODIFY `num_playlist` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=21;
--
-- AUTO_INCREMENT pour la table `podcast`
--
ALTER TABLE `podcast`
MODIFY `num_podcast` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=21;
--
-- AUTO_INCREMENT pour la table `podcasteur`
--
ALTER TABLE `podcasteur`
MODIFY `num_podcasteur` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=21;
--
-- AUTO_INCREMENT pour la table `son`
--
ALTER TABLE `son`
MODIFY `num_son` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=21;
--
-- Contraintes pour les tables déchargées
--
--
-- Contraintes pour la table `ecouter_podcast`
--
ALTER TABLE `ecouter_podcast`
ADD CONSTRAINT `ecouter_podcast_ibfk_1` FOREIGN KEY (`num_podcast`) REFERENCES `podcast` (`num_podcast`) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT `ecouter_podcast_ibfk_2` FOREIGN KEY (`num_conso`) REFERENCES `conso` (`num_conso`) ON DELETE CASCADE ON UPDATE CASCADE;
--
-- Contraintes pour la table `ecouter_son`
--
ALTER TABLE `ecouter_son`
ADD CONSTRAINT `ecouter_son_ibfk_1` FOREIGN KEY (`num_son`) REFERENCES `son` (`num_son`) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT `ecouter_son_ibfk_2` FOREIGN KEY (`num_conso`) REFERENCES `conso` (`num_conso`) ON DELETE CASCADE ON UPDATE CASCADE;
--
-- Contraintes pour la table `podcast`
--
ALTER TABLE `podcast`
ADD CONSTRAINT `podcast_ibfk_1` FOREIGN KEY (`num_podcasteur`) REFERENCES `podcasteur` (`num_podcasteur`) ON DELETE CASCADE ON UPDATE CASCADE;
--
-- Contraintes pour la table `produit_son`
--
ALTER TABLE `produit_son`
ADD CONSTRAINT `produit_son_ibfk_1` FOREIGN KEY (`num_artiste`) REFERENCES `artiste` (`num_artiste`) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT `produit_son_ibfk_2` FOREIGN KEY (`num_album`) REFERENCES `album` (`num_album`) ON DELETE CASCADE ON UPDATE CASCADE;
--
-- Contraintes pour la table `ranger_son`
--
ALTER TABLE `ranger_son`
ADD CONSTRAINT `ranger_son_ibfk_1` FOREIGN KEY (`num_playlist`) REFERENCES `playlist` (`num_playlist`) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT `ranger_son_ibfk_2` FOREIGN KEY (`num_son`) REFERENCES `son` (`num_son`) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT `ranger_son_ibfk_3` FOREIGN KEY (`num_conso`) REFERENCES `conso` (`num_conso`) ON DELETE CASCADE ON UPDATE CASCADE;
--
-- Contraintes pour la table `son`
--
ALTER TABLE `son`
ADD CONSTRAINT `son_ibfk_1` FOREIGN KEY (`num_album`) REFERENCES `album` (`num_album`) ON DELETE CASCADE ON UPDATE CASCADE;
COMMIT;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;

SQL Requête / query
une requête SQL simple pour sélectionner tous les sons et les trier par ordre alphabétique de leur titre
SELECT *
FROM `son`
ORDER BY `titre_son` ASC;
les sons triés par titre ainsi que les noms de leurs artistes, nous allons joindre les tables son, album, produit_son et artiste
SELECT s.titre_son, s.durée_son, a.nom_artiste
FROM `son` s
JOIN `album` al ON s.num_album = al.num_album
JOIN `produit_son` ps ON al.num_album = ps.num_album
JOIN `artiste` a ON ps.num_artiste = a.num_artiste
ORDER BY s.titre_son ASC;
une requête pour obtenir les titres des sons qui se trouvent dans une playlist dont le titre contient le mot "Jazz”
SELECT s.titre_son
FROM `son` s
JOIN `ranger_son` rs ON s.num_son = rs.num_son
JOIN `playlist` p ON rs.num_playlist = p.num_playlist
WHERE p.titre_playlist LIKE '%Jazz%';
la liste des titres des sons écoutés le 2024-11-01
SELECT s.titre_son, es.date_ecoute
FROM `son` s
JOIN `ecouter_son` es ON s.num_son = es.num_son
WHERE DATE(es.date_ecoute) = '2024-11-01';
les titres des sons qui se trouvent dans des albums de type "Jazz" ou "Rock”
SELECT s.titre_son, al.titre_album
FROM `son` s
JOIN `album` al ON s.num_album = al.num_album
WHERE al.type_album IN ('Jazz', 'Rock');
la liste des différents types d'albums
SELECT DISTINCT type_album
FROM `album`;
la liste des podcasts dont le titre contient les caractères "IA”
SELECT titre_podcast
FROM `podcast`
WHERE titre_podcast LIKE '%IA%';
le nombre total de sons dans la table son
SELECT COUNT(*) AS nombre_de_sons
FROM `son`;
la liste des podcasts dont la durée est comprise entre 1500 et 2500 secondes
SELECT titre_podcast, durée_podcast
FROM `podcast`
WHERE durée_podcast BETWEEN 1500 AND 2500
ORDER BY durée_podcast;
la liste des podcasts réalisés par le podcasteur nommé "Marie Curie”
SELECT p.titre_podcast
FROM `podcast` p
JOIN `podcasteur` pc ON p.num_podcasteur = pc.num_podcasteur
WHERE pc.nom_podcasteur = 'Marie Curie';
Les bases de données NoSQL
Et la normalisation alors ?
Dans le monde NoSQL, la logique est assez différente de celle des bases relationnelles, il n’y a pas de normalisation.
- Le modèle relationnel repose sur la normalisation (éviter redondances → données séparées, jointures quand on les consulte).
- En NoSQL (documents, colonnes, graphes, clés/valeurs), on cherche souvent l’inverse : dénormaliser pour gagner en rapidité de lecture.
Exemple MongoDB (document store)
Tu peux stocker un étudiant et ses cours directement dans un seul document :
{
"id": 1,
"nom": "Julie",
"cours": [
{ "nom": "Math", "prof": "Dupont" },
{ "nom": "Info", "prof": "Martin" }
]
}
Pas besoin de 3 tables ni de jointures. Tout est imbriqué.
Alors, normalisation en NoSQL ?
- Il n’y a pas de règles strictes de normalisation comme dans le relationnel.
- Mais il existe des bonnes pratiques de modélisation :
- Éviter les duplications massives si elles posent problème (par exemple, stocker l’email d’un prof dans chaque document étudiant → compliqué à maintenir).
- Choisir entre embedding (imbriquer) ou referencing (référencer) en fonction des besoins :
- Embedding = plus rapide en lecture, mais redondant.
- Referencing = plus proche d’une logique relationnelle, mais demande plus de requêtes.
dans NoSQL, pas de normalisation au sens Codd, mais tu fais des choix entre dénormaliser pour les performances ou garder des références pour la cohérence.
Comparaison normalisé / non normalisé
Parfait, voici un petit parallèle visuel SQL vs NoSQL autour du même exemple “Étudiants – Cours – Profs”.
🔹 Modèle relationnel (SQL normalisé)
Trois tables séparées, reliées par clés étrangères.
- *Etudiants**
| id | nom |
|----|-------|
| 1 | Julie |
| 2 | Karim |
| 3 | Sam |
- *Cours**
| id | nom | prof_id |
|----|-------|---------|
| 10 | Math | 100 |
| 11 | Info | 101 |
- *Profs**
| id | nom |
|-----|--------|
| 100 | Dupont |
| 101 | Martin |
- *Inscriptions**
| etudiant_id | cours_id |
|-------------|----------|
| 1 | 10 |
| 1 | 11 |
| 2 | 11 |
| 3 | 10 |
👉 Avantage : aucune redondance.
👉 Inconvénient : il faut faire des jointures pour reconstruire l’info.
🔹 Modèle document (NoSQL, style MongoDB)
Tout est stocké dans un document unique par étudiant.
{
"id": 1,
"nom": "Julie",
"cours": [
{ "nom": "Math", "prof": "Dupont" },
{ "nom": "Info", "prof": "Martin" }
]
}
Avantage : une seule lecture te donne tout.
Inconvénient : si “Dupont” change de nom, il faut mettre à jour ce prof dans tous les documents où il apparaît.
- SQL = normalisation → cohérence, moins de redondance.
- NoSQL = souvent dénormalisation → performance, simplicité d’accès.
- Si tu as besoin que Dupont soit unique et toujours cohérent → SQL est ton ami.
- Si ton enjeu, c’est de répondre à des millions de requêtes/seconde avec des données pas toujours à jour à la milliseconde près → NoSQL fait le job.
Plusieurs tables dans NoSQL ?
En NoSQL, on ne dit pas le mot « table ». Chaque famille de bases a son vocabulaire :
- MongoDB (document store) → tu as une base de données qui contient plusieurs collections, chaque collection ressemble à une table, et elle contient des documents JSON.
- Cassandra / BigTable (colonnes) → tu as des column families, proches de tables mais avec une structure plus flexible.
- Redis (clé-valeur) → tu as un espace clé/valeur global, mais tu peux grouper tes données par préfixes de clé pour simuler des ensembles.
- Neo4j (graphes) → tu n’as pas de tables, mais des nœuds et des relations.
On peut avoir plusieurs “ensembles de données” distincts dans une même base NoSQL, comme on aurait plusieurs tables dans un SQL.
La différence, c’est que ces ensembles sont moins strictement structurés que des tables relationnelles.
Les bases de données NoSQL fonctionnent différemment des bases relationnelles (SQL) en raison de leur architecture flexible et évolutive. Voici les principaux concepts à comprendre :
Définition d’un BD NosQL
Les bases de données NoSQL (Not Only SQL) sont conçues pour stocker et manipuler des données non structurées ou semi-structurées de manière efficace, sans avoir recours aux tables et relations classiques des bases SQL.
Caractéristiques principales
- Scalabilité horizontale : Elles peuvent être réparties sur plusieurs serveurs (sharding).
- Flexibilité du schéma : Contrairement aux bases SQL, elles n’ont pas de schéma rigide, ce qui permet d’ajouter ou modifier des champs dynamiquement.
- Performance optimisée pour certaines opérations : Elles sont souvent utilisées pour des lectures/écritures rapides sur de gros volumes de données.
- Modèles de données variés : Elles supportent plusieurs modèles de stockage (clé-valeur, document, colonne, graphe).
Les différents types de bases NoSQL
Il existe quatre grandes catégories de bases NoSQL, chacune adaptée à des cas d’utilisation spécifiques :
- Bases clé-valeur
- Principe : Stockent les données sous forme de paires clé → valeur.
- Exemples : Redis, Amazon DynamoDB
- Cas d’utilisation : Caching, sessions utilisateur, files d’attente en temps réel.
- Bases orientées documents
- Principe : Stockent les données sous forme de documents (JSON, BSON, XML).
- Exemples : MongoDB, CouchDB, Firebase Firestore
- Cas d’utilisation : Applications web et mobiles, e-commerce, gestion de contenus.
- Bases orientées colonnes
- Principe : Stockent les données en colonnes plutôt qu’en lignes, permettant une lecture rapide de certaines données.
- Exemples : Apache Cassandra, HBase
- Cas d’utilisation : Big Data, analytique, moteurs de recommandation.
- Bases orientées graphes
- Principe : Stockent les données sous forme de graphes (nœuds et relations).
- Exemples : Neo4j, ArangoDB
- Cas d’utilisation : Réseaux sociaux, recommandations, moteurs de recherche.
Comment fonctionnent-elles techniquement ?
- Partitionnement et Scalabilité
- Contrairement aux bases SQL qui scalent verticalement (ajout de puissance sur un serveur), les bases NoSQL scalent horizontalement en ajoutant des serveurs.
- Elles utilisent des techniques comme le sharding pour répartir les données entre plusieurs machines.
- Réplication et Tolérance aux pannes
- Elles répliquent souvent les données sur plusieurs serveurs pour éviter la perte de données en cas de panne.
- Utilisation de réplication maître-esclave ou réplication peer-to-peer.
- Indexation et Recherche
- Contrairement à SQL qui utilise des index B-Tree, les bases NoSQL utilisent des index adaptés à leurs modèles de données (ex. index inversés pour les bases documentaires).
- Consistance, Disponibilité et Partitionnement (CAP)
- Le théorème CAP indique qu’une base NoSQL ne peut garantir que deux des trois propriétés suivantes :
- Consistance : Tous les nœuds ont les mêmes données à tout moment.
- Disponibilité : Le système répond toujours aux requêtes, même en cas de panne.
- Tolérance au partitionnement : Fonctionne même si une partie du réseau est coupée.
- Par exemple, MongoDB privilégie la disponibilité et le partitionnement, tandis que Cassandra favorise la disponibilité et la scalabilité.
- Le théorème CAP indique qu’une base NoSQL ne peut garantir que deux des trois propriétés suivantes :
Avantages et Inconvénients
- Avantages :
- Très scalable et performant sur de gros volumes de données.
- Modèle de données flexible (pas de schéma rigide).
- Adapté aux données non structurées (JSON, graphes, colonnes).
- Bonne gestion de la distribution des données (cloud, clusters).
- Inconvénients :
- Pas de requêtes SQL standardisées, chaque base a son propre langage.
- Moins de garantie d’intégrité des données (pas de contraintes comme en SQL).
- Complexité accrue pour certaines opérations (ex. jointures, transactions).
Cas d’utilisation courants
- Réseaux sociaux (Facebook, Twitter utilisent du NoSQL pour stocker les relations entre utilisateurs).
- IoT et Big Data (Apache Cassandra est souvent utilisé pour gérer des flux massifs de données).
- E-commerce (MongoDB pour stocker des fiches produits avec des structures variées).
- Moteurs de recommandation (Neo4j pour stocker et analyser des relations complexes).
Exemple d’utilisation avec MongoDB
Un document dans MongoDB ressemble à ceci :
{
"_id": "12345",
"nom": "Alice",
"email": "alice@example.com",
"commandes": [
{
"id_commande": "A1",
"produit": "Ordinateur",
"prix": 1200
},
{
"id_commande": "A2",
"produit": "Clavier",
"prix": 100
}
]
}Ici, nous avons un document JSON représentant un utilisateur avec ses commandes, sans nécessité de jointure.
Conclusion
Les bases NoSQL sont puissantes pour des applications nécessitant scalabilité, flexibilité et performances, mais elles ne remplacent pas totalement les bases SQL, surtout pour les transactions complexes. Leur choix dépend donc du cas d’utilisation et des contraintes du projet.
Pourquoi choisir MongoDB plutôt qu'une base SQL pour une application web ?
MongoDB peut être un meilleur choix qu'une base de données SQL pour une application web dans plusieurs cas, en raison de ses caractéristiques spécifiques.
Flexibilité du Schéma
- Avantages MongoDB
- Stocke les données sous forme de documents JSON/BSON, ce qui permet d'avoir des structures flexibles
- Pas besoin de définir un schéma strict à l'avance
- Idéal pour les applications web où les données peuvent évoluer (ex. ajouter un champ sans modifier toute la base)
- Inconvénients SQL
- Nécessite un schéma défini à l'avance
- Toute modification du schéma peut nécessiter des migrations complexes
- Cas d'utilisation
- Si ton application web gère des profils utilisateurs, certains utilisateurs peuvent avoir des champs différents (ex. champs de réseaux sociaux facultatifs)
- Un e-commerce où les fiches produits ont des attributs variables
Scalabilité Horizontale (Sharding)
- Avantages MongoDB
- Scalable horizontalement : peut distribuer les données sur plusieurs serveurs facilement
- Utilise le sharding (partitionnement des données sur plusieurs machines)
- Inconvénients SQL
- Scalabilité verticale (ajouter plus de puissance au serveur) ou réplication (qui ne gère pas bien les gros volumes de lecture/écriture)
- Les bases SQL ont du mal à supporter des millions d'utilisateurs simultanés sans optimisation complexe
- Cas d'utilisation
- Si ton application web a un grand nombre d'utilisateurs et nécessite de gérer des requêtes simultanées (ex. réseaux sociaux, SaaS, applications mobiles connectées)
Rapidité des Requêtes
- Avantages MongoDB
- Accès rapide aux documents grâce aux index et stockage en JSON natif
- Les requêtes sont optimisées pour les grands volumes de données sans jointures complexes
- Inconvénients SQL
- Les jointures entre tables peuvent ralentir les performances
- Nécessite une optimisation plus poussée des index
- Cas d'utilisation
- Applications nécessitant des requêtes rapides comme les moteurs de recommandation, dashboards analytiques
Gestion des Données Non Structurées et Complexes
- Avantages MongoDB
- Permet d'imbriquer des données sous forme d'objets JSON
- Exemple : Une liste de commandes peut être stockée directement dans l'utilisateur
{ "nom": "Alice", "email": "alice@example.com", "commandes": [ { "id": "A1", "produit": "Ordinateur", "prix": 1200 }, { "id": "A2", "produit": "Clavier", "prix": 100 } ] }
- Inconvénients SQL
- Ici, tu aurais besoin d'une table "utilisateurs" et une autre "commandes", puis de faire une jointure
- Cas d'utilisation
- Si ton application a des relations hiérarchiques complexes (ex. commentaires imbriqués, forums, réseaux sociaux)
Déploiement et Intégration avec le Cloud
- Avantages MongoDB
- Compatible avec les services cloud (MongoDB Atlas, AWS, Google Cloud)
- Gestion automatique de la scalabilité et des sauvegardes
- Inconvénients SQL
- Peut être plus lourd à configurer dans un environnement cloud-first
- Cas d'utilisation
- Si ton application est hébergée sur le cloud et doit s'adapter dynamiquement aux charges (ex. pics de trafic soudains)
Meilleure Gestion du Big Data et des Microservices
- Avantages MongoDB
- Fonctionne bien avec les architectures microservices où chaque service gère ses propres données
- Compatible avec les traitements de Big Data et les bases distribuées
- Inconvénients SQL
- Moins adapté aux architectures modernes et distribuées
- Cas d'utilisation
- Applications web utilisant des API REST, GraphQL avec des services indépendants
Quand SQL reste un meilleur choix ?
MongoDB n'est pas toujours mieux que SQL. Voici des cas où une base SQL peut être plus appropriée :
Transactions complexes et ACID
- Si ton application gère des transactions bancaires, des paiements ou de la comptabilité, une base SQL garantit une intégrité parfaite des données
Rapports et analyses complexes
- Si tu fais beaucoup de requêtes analytiques avec des jointures complexes, PostgreSQL ou MySQL peuvent être plus adaptés
Taille modérée des données
- Si ton application n'a pas besoin d'un gros volume de données ni d'une scalabilité horizontale, SQL peut être suffisant
Conclusion : MongoDB est-il meilleur pour ton application web ?
OUI, si :
- Ton application a des données non structurées ou en constante évolution
- Tu veux scaler facilement sans migrer de schéma
- Tu cibles une architecture cloud-native et microservices
- Les performances sont plus importantes que l'intégrité stricte des transactions
NON, si :
- Tu gères des transactions complexes et critiques
- Tu as besoin de jointures fréquentes et de fortes contraintes d'intégrité
- Ton projet a un besoin de reporting avancé
Si ton application web est dynamique et évolutive, MongoDB est un excellent choix. Si c'est un projet avec des règles de gestion strictes, un SQL comme PostgreSQL peut être plus adapté.
Comment Spotify utilise SQL et NoSQL
Spotify utilise une combinaison de bases de données SQL et NoSQL en fonction des besoins spécifiques de chaque service de son architecture.
Pourquoi Spotify ne se limite pas à SQL ?
Spotify est une plateforme qui gère des millions d'utilisateurs actifs et doit :
- Stocker et gérer des milliards de chansons et playlists
- Offrir une expérience fluide et rapide, même sous forte charge
- Assurer une scalabilité massive pour supporter les pics d'utilisation
- Traiter en temps réel les recommandations, les recherches et le streaming
Pour cela, une seule base de données ne suffit pas. Spotify utilise une approche hybride avec plusieurs technologies de stockage.
Bases SQL utilisées par Spotify
Spotify utilise PostgreSQL pour certaines tâches spécifiques :
- Gestion des utilisateurs (comptes, abonnements, préférences)
- Données structurées et relationnelles
- Transactions nécessitant une forte cohérence (facturation, abonnements premium)
Pourquoi PostgreSQL ?
- PostgreSQL est robuste et fiable pour gérer des transactions critiques
- Supporte des requêtes SQL avancées et une forte cohérence ACID
Bases NoSQL utilisées par Spotify
Spotify utilise également des bases NoSQL pour gérer des tâches nécessitant une haute disponibilité et scalabilité :
1. Cassandra
- Stocke les informations sur les lectures de chansons
- Gère les logs d'activité et les historique d'écoutes
- Permet de scaler horizontalement sans perte de performance
2. Apache Kafka
- Utilisé pour le traitement de flux de données en temps réel
- Gère les événements, comme la lecture d'une chanson, la création d'une playlist
- Permet de distribuer ces données entre différents services
3. Elasticsearch
- Utilisé pour la recherche rapide de chansons, artistes, playlists
- Optimisé pour les recherches textuelles et suggestions
4. Redis
- Utilisé pour le caching des requêtes fréquentes (ex : recommandations, playlists populaires)
- Réduit le temps de réponse des API
Pourquoi ne pas utiliser uniquement SQL ?
SQL est puissant, mais ne permet pas :
- Une scalabilité horizontale massive aussi facilement que NoSQL
- Un accès rapide aux données en temps réel, crucial pour le streaming
- Le stockage et le traitement efficace des logs et interactions utilisateur
Spotify utilise donc PostgreSQL pour les données critiques, et NoSQL (Cassandra, Redis, Elasticsearch, Kafka) pour la performance et la scalabilité.
Conclusion : Spotify utilise-t-il SQL ?
Oui, mais pas uniquement !
Spotify utilise PostgreSQL pour certaines parties relationnelles et transactionnelles. Mais pour la scalabilité et la gestion des flux de données massifs, ils s'appuient sur NoSQL et des solutions comme Cassandra, Kafka et Elasticsearch.
Si tu développes une application avec du streaming ou un fort volume de requêtes, une architecture hybride SQL + NoSQL est souvent une bonne approche.
CRÉÉR UNE BASE DE DONNÉES
- quand on est développeur on créé une base de données pour stocker les données et les informations
- on va faire des requêtes dans notre programme pour récupérer les données, mais aussi ajouter ou supprimer des données dans la BD
- On va créer une base de données
- MySQL
- Postgre
- Oracle
- MS SQL SERVER
MANIPULER SQL AVEC PHPMYADMIN
En ligne
BD
- https://www.phpmyadmin.net/try/
on peut exporter la BD pour l’importer plus tard et continuer l’exercice
SQL
Sur windows
Pour installer phpMyAdmin sur Windows, vous pouvez suivre les étapes suivantes. phpMyAdmin nécessite un serveur Web (comme Apache) et une base de données MySQL ou MariaDB. Le plus simple est d'utiliser un package comme XAMPP qui inclut Apache, MySQL et PHP, facilitant l'installation.
Étapes pour installer phpMyAdmin via XAMPP
- Télécharger XAMPP :
- Allez sur le site officiel de XAMPP.
- Téléchargez le fichier d'installation pour Windows et installez-le en suivant les instructions.
- Pendant l'installation, assurez-vous de sélectionner Apache, MySQL et phpMyAdmin.
- Lancer XAMPP :
- Ouvrez le Panneau de contrôle XAMPP et démarrez les services Apache et MySQL en cliquant sur "Start" à côté de chaque module.
- Accéder à phpMyAdmin :
- Une fois Apache et MySQL en cours d'exécution, ouvrez un navigateur et entrez l'URL suivante :
http://localhost/phpmyadmin
- phpMyAdmin devrait s'ouvrir et afficher une interface pour gérer vos bases de données MySQL.
- Une fois Apache et MySQL en cours d'exécution, ouvrez un navigateur et entrez l'URL suivante :
Configuration de phpMyAdmin
- MOT DE PASSE ROOT
Si vous souhaitez définir un mot de passe pour l'utilisateur root (ou pour d'autres utilisateurs) :- Dans phpMyAdmin (http://localhost/phpmyadmin), allez dans l'onglet Utilisateurs et modifiez le mot de passe de l'utilisateur
root.
- Une fois cela fait, mettez à jour le fichier de configuration de phpMyAdmin pour que la connexion fonctionne correctement :
- Ouvrez le fichier
config.inc.phpde phpMyAdmin (généralement situé dans le dossierC:\xampp\phpMyAdmin).
- Recherchez la ligne avec
$cfg['Servers'][$i]['password']et ajoutez le mot de passe que vous avez défini.
- Ouvrez le fichier
- Dans phpMyAdmin (http://localhost/phpmyadmin), allez dans l'onglet Utilisateurs et modifiez le mot de passe de l'utilisateur
- ACTIVER LA RÉÉCRITURE D’URL SUR APACHE
Assurez-vous que le module
mod_rewriteest activé sur Apache. Voici comment vérifier cela sous MAMP :- Ouvrez le fichier
httpd.conf:- Dans XAMPP, ce fichier se trouve généralement dans
C:\xampp\conf\apache\httpd.conf.
- ou bien depuis le panneau de configuration XAMPP dans le bouton “Config” en face du service Apache
- Dans XAMPP, ce fichier se trouve généralement dans
- Recherchez et dé commentez
mod_rewrite:- Recherchez la ligne suivante dans le fichier et upprimez le
#au début de la ligne pour activer le module ::#LoadModule rewrite_module modules/mod_rewrite.so
- Recherchez la ligne suivante dans le fichier et upprimez le
- Activer les fichiers
.htaccess:- Dans le même fichier, recherchez la directive
AllowOverrideet assurez-vous qu’elle est définie surAllpour votre répertoire racine. Par exemple :<Directory "/path/to/your/project"> AllowOverride All </Directory>
- Dans le même fichier, recherchez la directive
- Redémarrez Apache :
- Retournez dans XAMPP et redémarrez les serveurs pour appliquer les modifications.
- Ouvrez le fichier
Agence digitale Parisweb.art
Tout savoir sur Julie, notre directrice de projets digitaux : LinkedIn